Chains
BNB Beacon Chain
BNB ecosystem’s staking & governance layer
Staking
Earn rewards by securing the network
Build
Explore
Accelerate
Connect
A Technical Deep-Dive on the JIT/AOT Compiler for revm of BNB Chain

TL;DR
- EVM interpretation has hit a performance ceiling due to dispatch and emulation overhead.
- revmc compiles EVM bytecode into native machine code using JIT/AOT, removing interpreter bottlenecks.
- Compute-heavy workloads see the largest gains (up to 6.9×); state-heavy ones are limited by bridge crossings.
- AOT eliminates JIT warm-up time by preloading native binaries for high-volume contracts.
- The long-term path is AOT-as-a-Service for the most-used contracts on BNB Chain.
Section 1: The Problem Space: The Inevitable Performance Ceiling of EVM Interpretation
1.1 The Central Thesis: reth's Performance Mandate
The reth (Rust based client) is architected from the ground up with a singular, driving mandate: to be the most performant, modular, and state-of-the-art execution client in the EVM ecosystem. This pursuit of performance informs every component, from its parallelized sync stages to its database-agnostic state layer. Within this complex system, however, all activity eventually converges on a single, critical component: the Ethereum Virtual Machine (EVM).
The heart of reth's execution layer is revm, a highly-optimized, next-generation EVM implementation written in Rust. revm is, by many metrics, one of the fastest EVM interpreters in existence. It has achieved this through meticulous optimization of its core dispatch loop, efficient state handling, and Rust's low-level performance guarantees.
However, revm is approaching the asymptotic limit of what an interpreter-based model can achieve. This limitation is known as the "Interpreter's Performance Ceiling." An interpreter, by its very nature, operates as a "one-opcode-at-a-time" processor. Its core logic is fundamentally a large while loop containing a match (or switch) statement that dispatches to a corresponding Rust function for each EVM opcode (e.g., ADD, SLOAD, JUMP).
This architecture incurs two significant, non-reducible overheads:
- Dispatch Overhead: The cost of the match statement itself—branch prediction misses, instruction cache pressure, and the general overhead of the loop—is paid for on every single opcode.
- Emulation Overhead: Each opcode function (e.g., op_add) must perform its work within the host Rust context. This involves fetching operands from a virtual stack (a Vec or similar structure), performing the operation, and pushing the result back. This is an "emulation" of a real CPU, and it adds a constant-factor overhead to every instruction.
revm is brilliant at minimizing this overhead, but it cannot eliminate it. The interpreter's fundamental "fetch-decode-execute" cycle, running on top of the host CPU's own fetch-decode-execute cycle, establishes a hard performance ceiling that no further optimization can break through.
1.2 Insight of revmc: A Paradigm Shift from Interpretation to Compilation of BNB Chain
The revmc project is the solution to this performance ceiling. It represents a fundamental paradigm shift for revm, moving it from a highly-optimized interpreter to a high-performance virtual machine runtime that utilizes compilation technology. This is not a mere optimization of the existing revm code; it is a replacement of its core execution engine.
revmc aims to accelerate EVM execution by transforming EVM bytecode—the language of smart contracts—directly into native machine code (e.g., x86_64, ARM64) that can be executed by the host CPU. This process, managed via Just-in-Time (JIT) or Ahead-of-Time (AOT) strategies, completely eliminates the interpreter's dispatch loop. E.g. Instead of emulating an ADD opcode, revmc generates the single native add instruction that the host CPU understands.
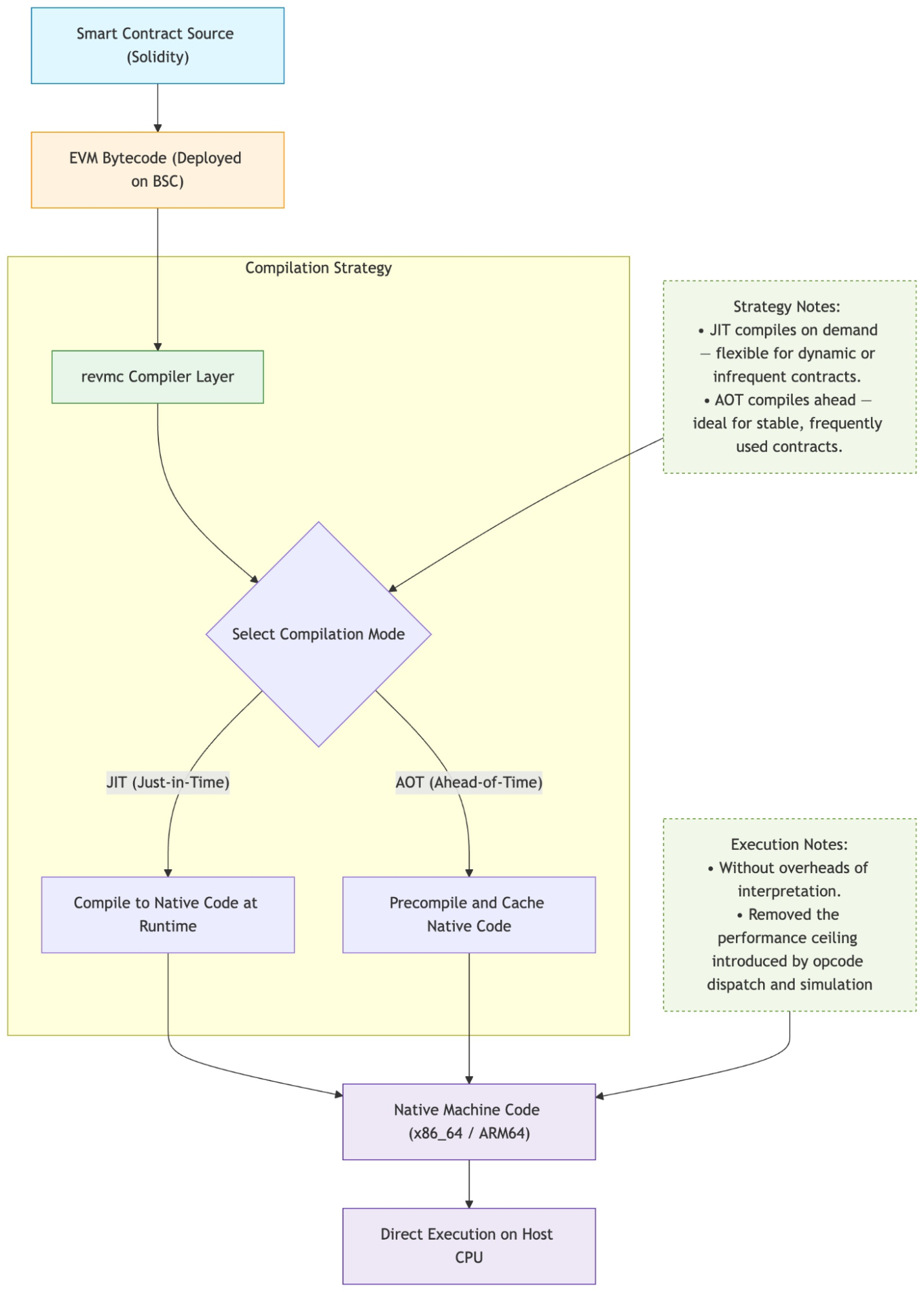
At BNB Chain, we aim to make a major strategic pivot for revm and reth. The next frontier for onchain performance lies in compilation. This is a significantly more complex engineering challenge, but it is one that offers non-linear performance gains, moving EVM execution from "emulated" speed to "native" speed
Section 2: System Architecture: Deconstructing the revmc Compiler
The revmc architecture is a sophisticated system composed of three primary components: the bridge for state communication, a dual JIT/AOT compiler engine, and the LLVM compiler backend. This section clarifies how these components interact and where performance benefits or overheads arise.
2.1 The Bridge: The Interface Between Native Code and revm State
The single greatest challenge in a JIT compiler for a stateful VM is managing the boundary between the "unsafe," high-performance, compiled native code and the "safe," structured, host runtime. The high-level bridge that connects the compiled EVM code with the revm host's state management systems (like EVMData and the Journal).
The execution flow across this bridge is precise:
- revmc compiles a smart contract's EVM bytecode into native machine code.
- Computational opcodes like ADD, MUL, SHA3, or JUMP are compiled into their native equivalents, running entirely in the Compiled machine code.
- Stateful opcodes like SLOAD, SSTORE, BALANCE, or CALL are compiled into "thunks." A thunk is a small piece of code that prepares a function call to cross the bridge.
- When the native execution hits an SLOAD, it executes this thunk, which calls a safe, stable-ABI Rust function exposed by the revm host.
- Execution pauses in the native code and "crosses the bridge" back into the revm Rust environment.
- revm performs the requested SLOAD, handling all the complex logic: database lookups, state journaling, cache updates, and gas accounting.
- revm returns the result (the 32-byte value) back across the bridge to the native code.
- The native code receives the value and resumes execution at native speed.
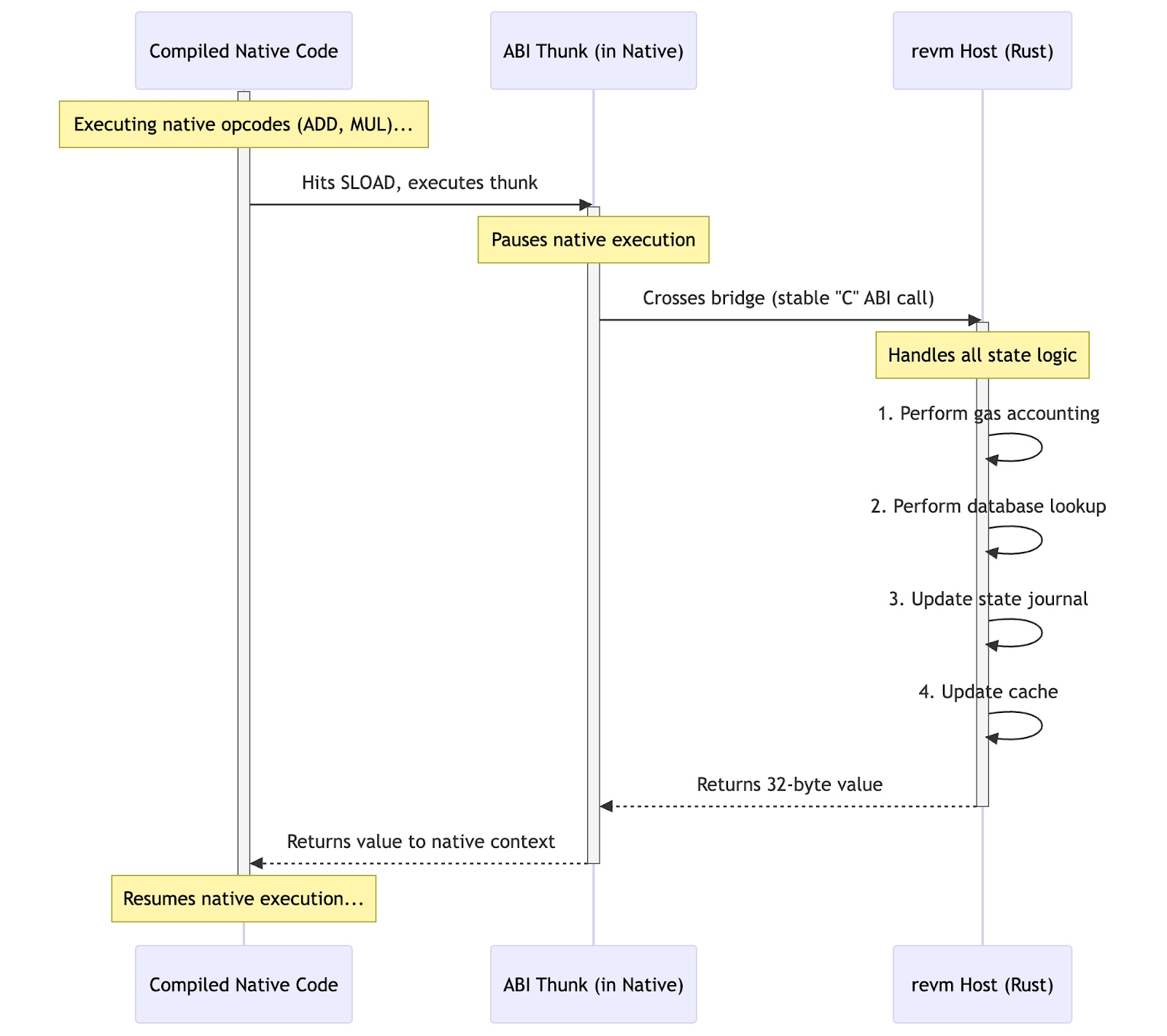
This architecture reveals a critical performance characteristic: the bridge acts as a context switch, and every crossing has a non-zero overhead. This creates a predictable performance model: the speedup provided by revmc will be inversely proportional to the number of stateful opcodes in a transaction.
- A computation-heavy contract (e.g., a cryptographic verifier with 1,000,000 ADD opcodes) will see an enormous, near-native speedup. The interpreter's 1,000,000 dispatch loops are replaced by 1,000,000 native add instructions, all executing without leaving the JIT-ed context.
- A state-heavy contract (e.g., a simple loop of 1,000 SSTOREs) will see a much more modest speedup. The bottleneck is not EVM execution; the bottleneck is the database I/O and the 1,000 context switches across the bridge. revmc can only optimize the few nanoseconds between each call.
Crucially, it is also the security boundary. The JIT-compiled code is, by definition, generated from untrusted user input (EVM bytecode). The bridge ensures this native code is sandboxed. It cannot directly access host memory, read the reth node's RAM, or interfere with the state of other transactions. It can only call the specific, safe, and heavily-validated functions exposed by the ABI.
2.2 The revmc Compiler Engine: A Dual JIT/AOT Strategy
revmc is designed as a sophisticated runtime, not just a simple compiler. It employs a dual-mode strategy to balance the trade-offs between performance and latency.
Mode 1: Just-in-Time (JIT) Compilation
This is the default mode for handling "hot" or newly-seen contracts. The JIT flow is dynamic and happens at runtime:
- A transaction is received for a contract.
- revm checks its code cache. If a native version of this contract exists, it jumps to step 9.
- If no native version exists, revm's "hotness" heuristic is triggered (e.g., this is the 5th time this contract has been called, or its gas limit is > 1,000,000).
- The contract's EVM bytecode is passed to the revmc compiler.
- revmc translates the EVM bytecode into an Intermediate Representation (IR).
- This IR is fed into the compiler backend.
- JIT Compiler performs optimizations and generates native machine code (e.g., x86_64) for the node's host CPU.
- This machine code is placed into an executable memory region (via mmap/mprotect), and a function pointer to its entry point is stored in the revm code cache.
- revm "jumps" to this native function pointer, bypassing the interpreter entirely.
The JIT model's primary flaw is the "warm-up problem." The first execution of a contract is now slower than the interpreter, because it must pay a one-time "JIT tax" (T_jit) for compilation.
Mode 2: Ahead-of-Time (AOT) Compilation
AOT compilation is revmc's solution to the warm-up problem. In this mode, compilation does not happen at runtime.
Instead, reth can be shipped with a pre-compiled cache of the most popular contracts on mainnet (e.g., the USDC proxy, the WETH contract, the Pancake V3 Router).
This strategy is a hallmark of sophisticated VM design:
- These compiled native binaries are bundled with the reth client.
- When a reth node starts, it pre-loads these binaries into its code cache.
- Most mainnet transactions, T_jit becomes zero. The node immediately finds the native version in its cache and executes it.
The AOT strategy effectively amortizes the compilation cost across all reth users, providing the raw speed of native execution (T_native) with the low-latency, "zero-warm-up" benefit of an interpreter.
Section 3: A Quantitative Analysis of revmc Performance on BNB Chain
3.1 Benchmark Methodology and Context
The primary benchmarks are drawn from the test suite that provides a diverse mix of workloads. These workloads are designed to stress different aspects of the EVM, from pure computation (e.g., fibonacci) and memory operations (e.g., mload_mstore) to state-heavy operations (e.g., sstore_write). All comparisons are run on identical hardware, with revmc's performance measured both with and without its one-time JIT compilation cost.
The key metrics are:
- Execution Time (ns/op): The raw wall-clock time to execute the benchmark.
- Compilation Overhead (μs): The one-time T_jit cost incurred by revmc on its first run.
- Speedup Factor: A ratio comparing the interpreter's execution time to revmc's.
3.2 Core Throughput Analysis: revmc vs. revm Interpreter
The headline finding is that revmc is, in a wide variety of use cases, significantly faster than the interpreter, with some computation-heavy benchmarks demonstrating speedups of 6.9x.
However, the aggregate numbers hide a more nuanced and important story. The performance gains are not uniform; they are highly dependent on the type of work being performed, which validates the architectural model described in Section 2.
- Computation-heavy benchmarks, such as fibonacci or loops with heavy ADD/MUL opcodes, show the most dramatic gains.
- State-heavy benchmarks, such as simple token transfers that are dominated by SLOAD and SSTORE operations, show more modest, though still significant, gains.
The following table provides a representative sample of these benchmark results:
Table 1: revmc vs. revm Interpreter: Core Execution Benchmarks
Repo: https://github.com/bnb-chain/revmc/tree/experimental/examples
Why results look like this
- Compute-heavy code benefits most from AOT/JIT (opcode dispatch removed, native CPU optimizations).
- Storage-heavy code is dominated by host crossings; dispatch is not the bottleneck, so AOT/JIT show smaller gains unless host crossings are reduced, amortized, or inlined/batched in-contract.
3.3 Making AOT/JIT work in latest revm/reth (what to consider)
- Version alignment: revmc-context and revm-handler must use the same revm_interpreter version (API changes across major versions are significant).
- Integration hook: use revm builder’s execute-frame override to dispatch by code hash (AOT/JIT vs interpreter), preserving full transact_commit semantics (validation, pre-exec, post-exec, commit).
- Host bridge: compiled code must use revm Host consistently (SLOAD/SSTORE/KECCAK/logs), no shortcuts; keep state/journal identical to interpreter.
- enable KZG precompile in revm-precompile (cryptographic primitive used by EIP-4844)
- Performance flags: use target-cpu=native, thin LTO, and asm-keccak consistently for both AOT/JIT and interpreter builds to ensure fair comparisons.
- Selection policy: allowlist by code hash (start small: WBNB/WETH/common routers); keep an interpreter fallback for safety and parity.
- Telemetry: measure AOT hits/misses, JIT compile time, avg per-call, and total block execution deltas; enable structured logging for fallbacks.
Section 4: Concluding Analysis and Future Outlook
4.1 Synthesis of Findings
The revmc project represents the logical evolution of the revm execution environment for BNB Chain. The analysis confirms the following:
- A Solved Problem: revm is at the peak of what an EVM interpreter can be. To achieve the next order-of-magnitude in performance, a paradigm shift to compilation is required.
- Quantifiable Validation: The benchmark data is clear. revmc provides game-changing speedups (6.9x) for computation-heavy workloads. This effectively creates a "two-speed" EVM where computation becomes nearly free, and state I/O (and bridge-crossing) becomes the new, dominant bottleneck.
4.2 Third-Order Implications: The Future of a revmc-Powered Ecosystem
Once revmc is stable, reth will become the leading execution client for computationally-demanding tasks. For years, the EVM gas model has trained Solidity developers to think in a specific way: "computation is expensive, storage is (relatively) cheap." Developers are taught to avoid for loops and complex on-the-fly math. They are encouraged to use SSTORE to cache intermediate results to save gas on future calls.
revmc flips this entire model on its head.
In the revmc world, the wall-clock time cost is the inverse:
- Computation (e.g., ADD, MUL): Almost free. The 10-gas MUL takes a few nanoseconds.
- Storage (e.g., SSTORE): The new bottleneck. The 20,000-gas SSTORE is just as slow as it was before, dominated by I/O and the bridge context switch.
This will usher in an era of "JIT-aware" smart contracts. We will see the rise of new protocols that perform complex, in-memory calculations, data transformations, or cryptographic verifications on-the-fly, avoiding SSTORE operations that are now (in wall-clock time) the most expensive thing a contract can do. This unlocks entirely new onchain use cases that were previously "too expensive" from a computational standpoint.
The Endgame: AOT-as-a-Service
The JIT/AOT dual strategy is the path forward. The logical endgame for this technology is an "AOT-as-a-Service" maintained by the BNB reth team. This service would monitor BNB mainnet, automatically AOT-compile the top 10,000 most-used contracts for all supported hard forks, and distribute these signed, verified native binaries as part of the reth client. This would eliminate JIT overhead for 99%+ of all transactions, finally achieving the dream: the raw performance of native code with the zero-latency, zero-warm-up of an interpreter.