Chains
BNB Beacon Chain
BNB ecosystem’s staking & governance layer
Staking
Earn rewards by securing the network
Build
Explore
Accelerate
Connect
Accelerating Smart Contract Execution on BSC with Super Instruction

TL;DR
- Super-Instructions fuse frequently used EVM bytecode sequences into single opcodes, cutting execution overhead.
- Performance gains on BSC: 15% faster execution, 14% faster sync, 17% higher throughput.
- No impact on consensus or tooling: Optimizations are local, length-preserving, and fully compatible.
- Benefits for builders: smoother execution, lower node costs, and stronger scalability for real-world workloads.
Introduction
BSC processes billions of transactions, and many of them look alike. Around 60% of mainnet transactions are repetitive DeFi interactions, such as swaps on PancakeSwap. These patterns cause the EVM to re-run identical instruction fragments across the network, over and over.
This repetition leads to wasted cycles: the interpreter dispatches the same sequences repeatedly, shuffling the stack in the same way each time.
Super-Instructions are BSC’s answer. By replacing hot bytecode sequences with a single custom opcode, execution becomes more efficient. Instead of executing ten steps, the interpreter executes one atomic operation.
For developers, auditors, and node operators, the benefits are concrete:
- Developers get faster, cheaper execution for their contracts without changing a line of code.
- Auditors keep tooling and offsets intact, since optimized bytecode is length-preserving.
- Node operators see faster block processing and lower resource use.
Importantly, super-instructions are consensus neutral. On-chain bytecode remains unchanged; optimizations happen only during local execution.
BSC identifies high-frequency bytecode sequences from mainnet traffic, scoring them by (length × frequency) and resolving overlaps using a greedy graph-based selection.
For builders, this means contracts run faster on BSC without any changes to source code or deployment. For node operators, blocks sync more quickly and use fewer resources.
Super-Instruction Optimization in BSC
Super-instructions are not new in computer science, but BSC’s approach combines two innovations:
- A data-driven pipeline that mines frequent bytecode sequences directly from mainnet traffic, using the Re-Pair compression algorithm.
- A length-preserving transformation that guarantees compatibility with tools, debuggers, and consensus.
Together, these improvements mean optimizations are practical, safe, and beneficial at BSC scale.
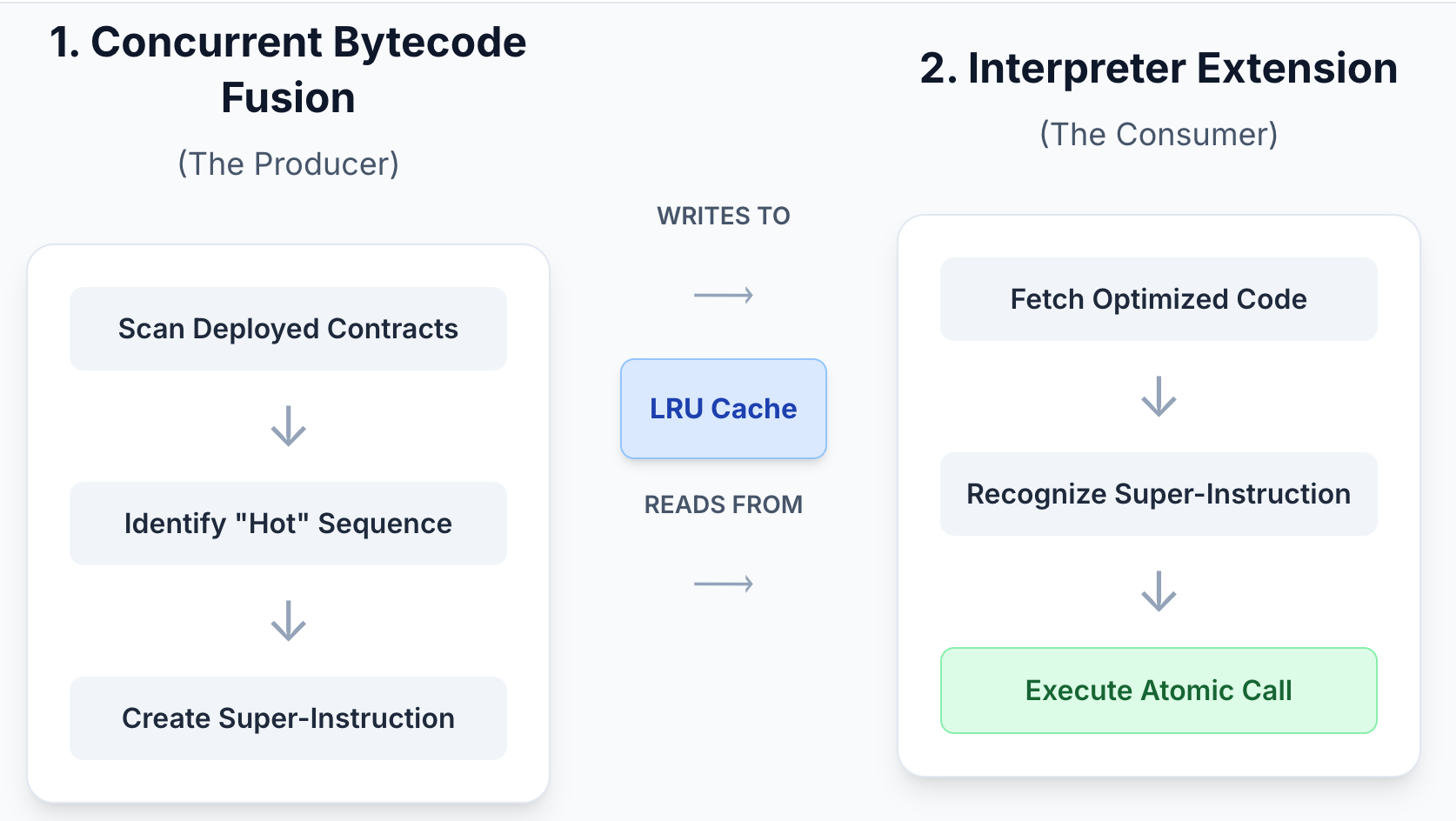
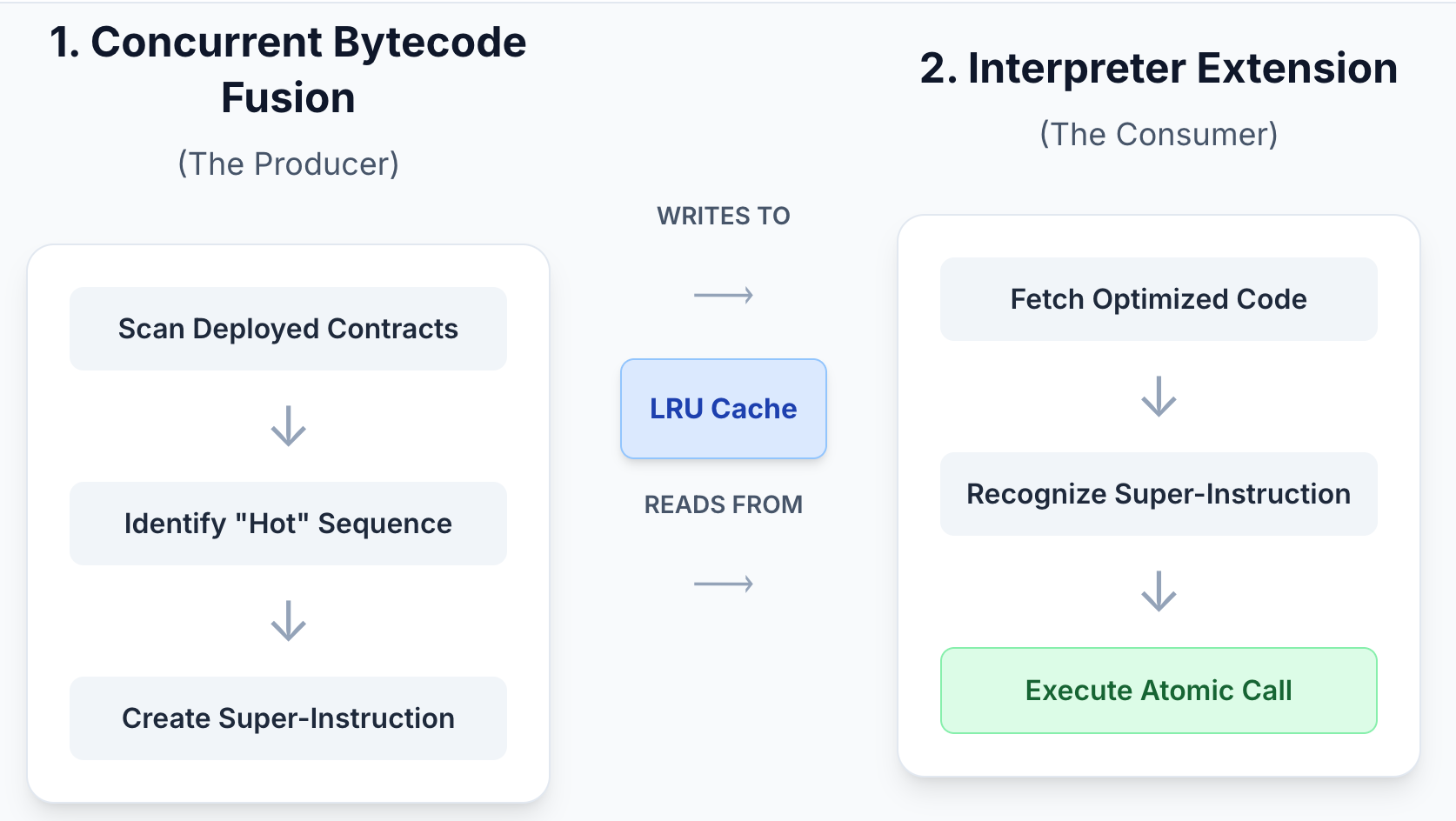
BSC implements them through two main components:
- Concurrent Bytecode Fusion – scans deployed contracts, fuses patterns into super-instructions, and caches results.
- Interpreter Extension – recognizes custom opcodes and executes entire sequences in one atomic handler.
1. Optimized Bytecode Generation (Background)
1.1 Feature Toggle
The optimization engine can be switched on or off at runtime. When off, the node behaves like unmodified Geth.
1.2 Task Dispatch & Parallelism
- Each new contract is checked against the cache by its codeHash.
- When a new contract byte-stream appears, the node calculates its codeHash and checks the in-memory LRU cache for an optimized version. If none exists, the tuple (codeHash, rawCode) is queued for optimization.
- On a cache miss, raw bytecode is queued.
- Background goroutines process this queue in parallel.
1.3 Basic-Block Construction via CFG
A control-flow graph (CFG) breaks contract bytecode into basic blocks, filtering out dead code and metadata. This guarantees correctness by excluding any dead code or metadata that could otherwise interfere with the optimization process.
1.4 Pattern Matching & Instruction Fusion
- The optimizer scans each block for high-frequency patterns.
- The first byte is replaced with a custom opcode.
- Remaining bytes are replaced with NOPs, preserving length.
1.5 Caching the Result
Optimized bytecode matches the original in length and offsets, guaranteeing valid control flow. Results are cached for future use, so popular contracts run faster with negligible overhead. Auxiliary artefacts such as jump analysis bit-vectors are cached separately for reuse.
Optimized contracts are generated once, then reused across future executions, making performance improvements cumulative over time.
2. Super-Instruction Execution (Foreground)
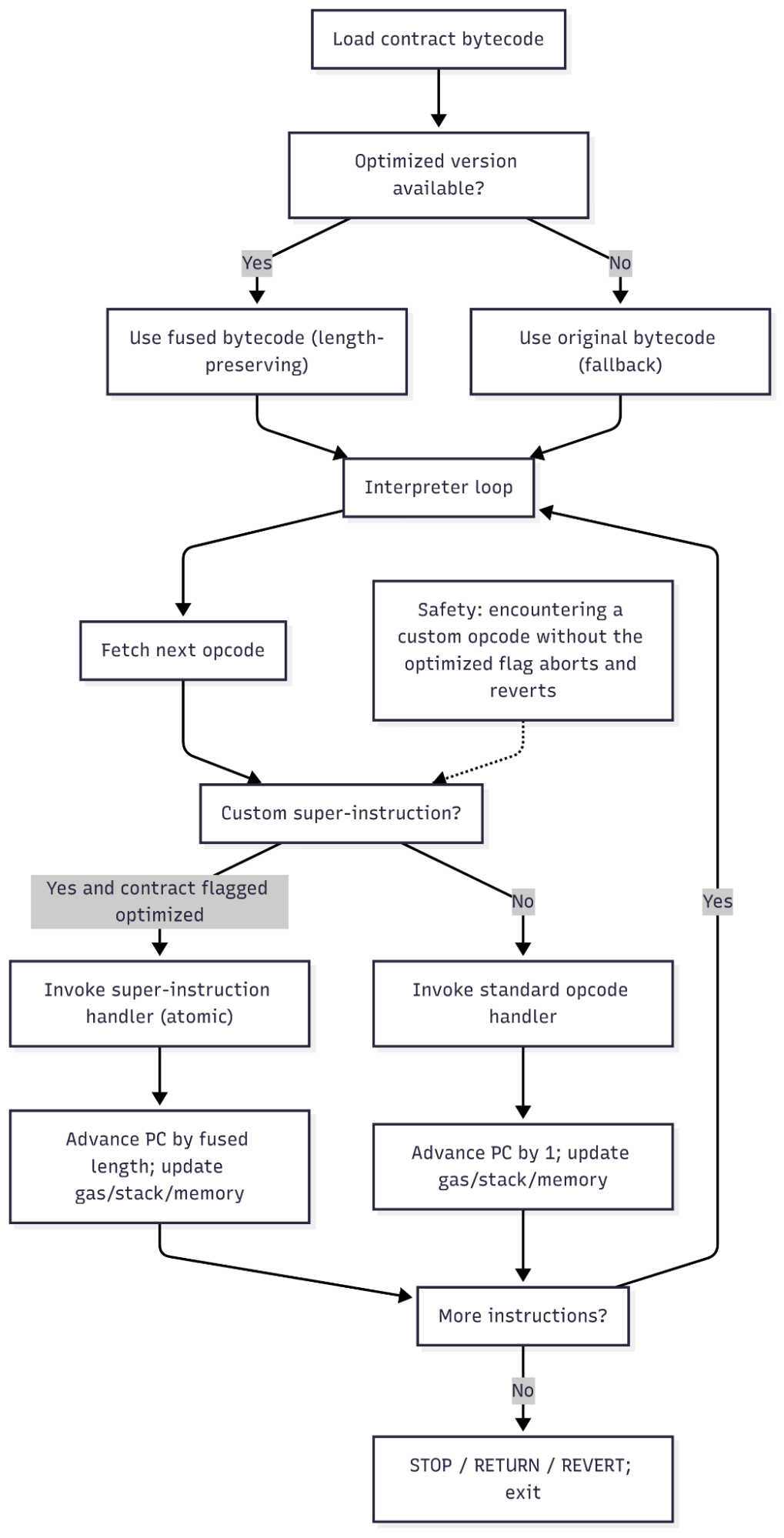
2.1 Loading Optimized Code
Before execution, the EVM checks the cache:
- Optimized version → load optimized code.
- No optimized version → run original bytecode.
If an optimized version exists, the contract is marked optimized before execution.
2.2 Dispatching Custom Bytecodes
The interpreter runs normally, but when it encounters a super-instruction byte, it calls a single handler instead of multiple standard ones.
2.3 Semantics of a Super-Instruction
- Each handler executes an entire sequence in one step.
- All stack/memory operations happen at once.
- For jumps, destinations are validated against the original map.
For example, a super-instruction may represent a full sequence such as: AND DUP2 ADD SWAP1 DUP2 LT.
2.4 Safety Measures
- Contracts containing a custom byte unintentionally will revert with a dedicated error.
- Jumps are always validated according to EVM rules.
The system is designed to fail safe: if anything goes wrong, execution automatically falls back to the original bytecode.
3. Super-Instruction Set Generation
BSC doesn’t manually define super-instructions. Instead, they are mined from real transaction data.
The process:
- Collect frequent instruction sequences.
- Apply Re-Pair compression to generate candidates.
- Score candidates as length × frequency.
- Use a graph-based algorithm to resolve overlaps.
- Select the top-scoring instructions.
When overlaps occur, scores are adjusted. For example, if Super-instruction A = (a, b, c) and B = (a, b, c, d, e), then selecting B reduces the frequency of A. Conversely, selecting A reduces the effective length of B to only (d, e), lowering its score. This ensures the Top-K selected instructions are non-redundant.
This ensures the instruction set evolves naturally with network usage, always targeting the most impactful patterns.
4. Compatibility & Safety
Benefit: Builders, auditors, and node operators can rely on stability while enjoying efficiency gains.
5. Performance Improvement
Benchmarks show tangible improvements under real workloads.
Sync Performance Results:
In the 24-hour mixed transaction sync test, blocks synced in 494 minutes compared to 575 minutes baseline, representing a 14% improvement.
Faster block execution means smoother syncing, higher throughput, and improved scalability for the entire ecosystem.
Conclusion and Future Improvements
Super-instructions make BSC execution faster, safer, and more efficient—without changing consensus or requiring developers to modify contracts.
These optimizations introduce no additional maintenance overhead for client operators and have zero impact on consensus.
Key benefits:
- Reduced interpreter overhead.
- Fewer stack operations.
- Asynchronous background generation.
- High cache hit rates for popular contracts.
Looking forward, the pipeline will be rerun periodically to adapt to new compiler output and application trends, ensuring that BSC continues to deliver efficiency gains where they matter most.
FAQ
1. How does this maintain consensus if different nodes are executing different bytecodes?
The key is that the optimization is a local execution speed-up that is semantically identical to the original bytecode. The on-chain bytecode remains the canonical version. Every super-instruction produces the exact same change to the EVM state (stack, memory, storage) as the original sequence of bytecodes it replaces. Therefore, the resulting state root of a block will be identical whether the node used the optimization or not. If a bug were to cause a semantic divergence, the node would fail to agree on the block's state root and fall out of sync, a failure that is self-contained.
2. What are the main security risks, and how are they mitigated?
The primary risk is a bug in the fusion engine or the super-instruction handler that causes incorrect execution. The document outlines several safety measures:
- Graceful Fallback: If any part of the optimization process fails, the EVM defaults to using the original, unmodified bytecode.
- Jump Destination Validation: All JUMP and JUMPI operations, even within a super-instruction, must validate the destination against the original bytecode's JUMPDEST map.
- Dedicated Error: If a contract was not marked as optimized but its code happens to contain a byte corresponding to a super-instruction bytecode, the interpreter will throw a specific error and revert the transaction, preventing accidental execution.
- Skipping Unsafe Code: The optimizer skips any basic blocks that already contain custom bytecodes or the INVALID bytecode to prevent unpredictable behavior.
3. How are new super-instruction patterns identified and deployed as compilers and contract patterns evolve?
This process is not static. To keep the optimization effective, the pipeline would need to be re-run periodically on up-to-date mainnet data. This would allow the BSC to:
- Identify new high-frequency patterns introduced by updated Solidity/Vyper compilers or new popular application types.
- Deprecate old super-instructions that are no longer common.
- Release the new, updated set of super-instructions with a new version of the client software.
4. Why replace the tail end of a pattern with NOPs instead of just removing the bytes and adjusting all jump offsets?
Adjusting all jump offsets in a contract would be a much more complex and fragile operation.
- Complexity: It would require a full control-flow analysis of the entire contract to correctly identify and rewrite every PUSH bytecode that places a jump destination on the stack.
- Brittleness: This approach could easily introduce subtle bugs if the analysis is not perfect.
- Tooling Incompatibility: External tools (like debuggers and decompilers) rely on the original bytecode offsets. Changing the code length would break them.
By using NOPs, the system preserves the original length and all offsets, making the transformation simple, robust, and transparent to external tooling. The super-instruction handler simply advances the program counter over the NOPs in a single step.
Follow us to stay updated on everything BNB Chain
Website | Twitter | Telegram | Facebook | dApp Store | YouTube | Discord | LinkedIn | Build N' Build Forum