Chains
BNB Beacon Chain
BNB ecosystem’s staking & governance layer
Staking
Earn rewards by securing the network
Build
Explore
Accelerate
Connect
Incremental Snapshot: Making BSC Node Operation Faster and Lighter

TL;DR
- Incremental snapshot reduces monthly data requirements for clients from 1TB+ to ~120GB.
- Incremental snapshots enable pipeline downloading and merging to run BSC nodes faster, which can speed up your node synchronization dramatically when your node is out of sync by avoiding downloading the full snapshot again but using incremental snapshot.
- No more massive downloads or high bandwidth bottlenecks.
- Fully compatible with both traditional full snapshots and new incremental approach.
Introduction
BNB Smart Chain (BSC) has undergone significant evolution in block production speed. With block time reduction from 3 seconds to 1.5 seconds, and further to 750ms, the network now produces approximately 4 times more blocks compared to the original rate.
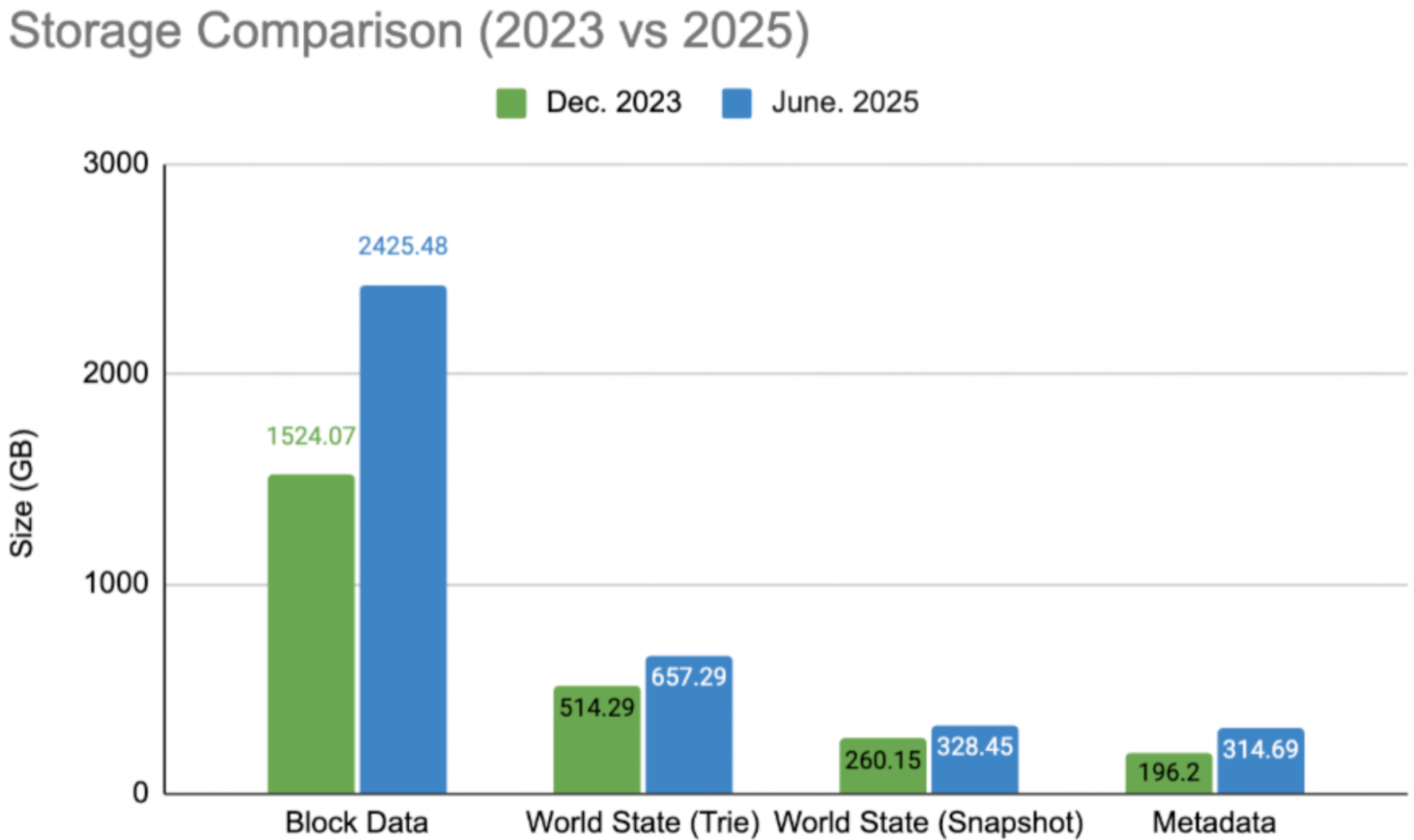
But faster blocks also mean bigger storage requirements for nodes. In just 18 months, storage requirements size grew from 2.49TB (Dec 2023) → 3.72TB (Jun 2025), a nearly 50% increase. For many developers and node operators, downloading and syncing snapshots now takes 13+ hours, creating a real barrier to participation.
Challenges with Traditional Snapshots:
- Poor User Experience: Lengthy download times negatively impact users.
- High Barrier to Entry: Increased storage and bandwidth demands deter new operators.
- Developer Inefficiency: Developers experience slower time-to-productivity.
Incremental Snapshots: The Solution
Incremental snapshots address these issues by providing smaller, regular updates instead of large, infrequent downloads. This approach leads to:
- Faster node onboarding and synchronization.
- Reduced operational costs.
- Increased participation within the BSC ecosystem.
Incremental Snapshot Architecture
Incremental snapshots fundamentally change how BSC nodes catch up with network state. Instead of downloading everything at once, the system uses a base-plus-increments model.
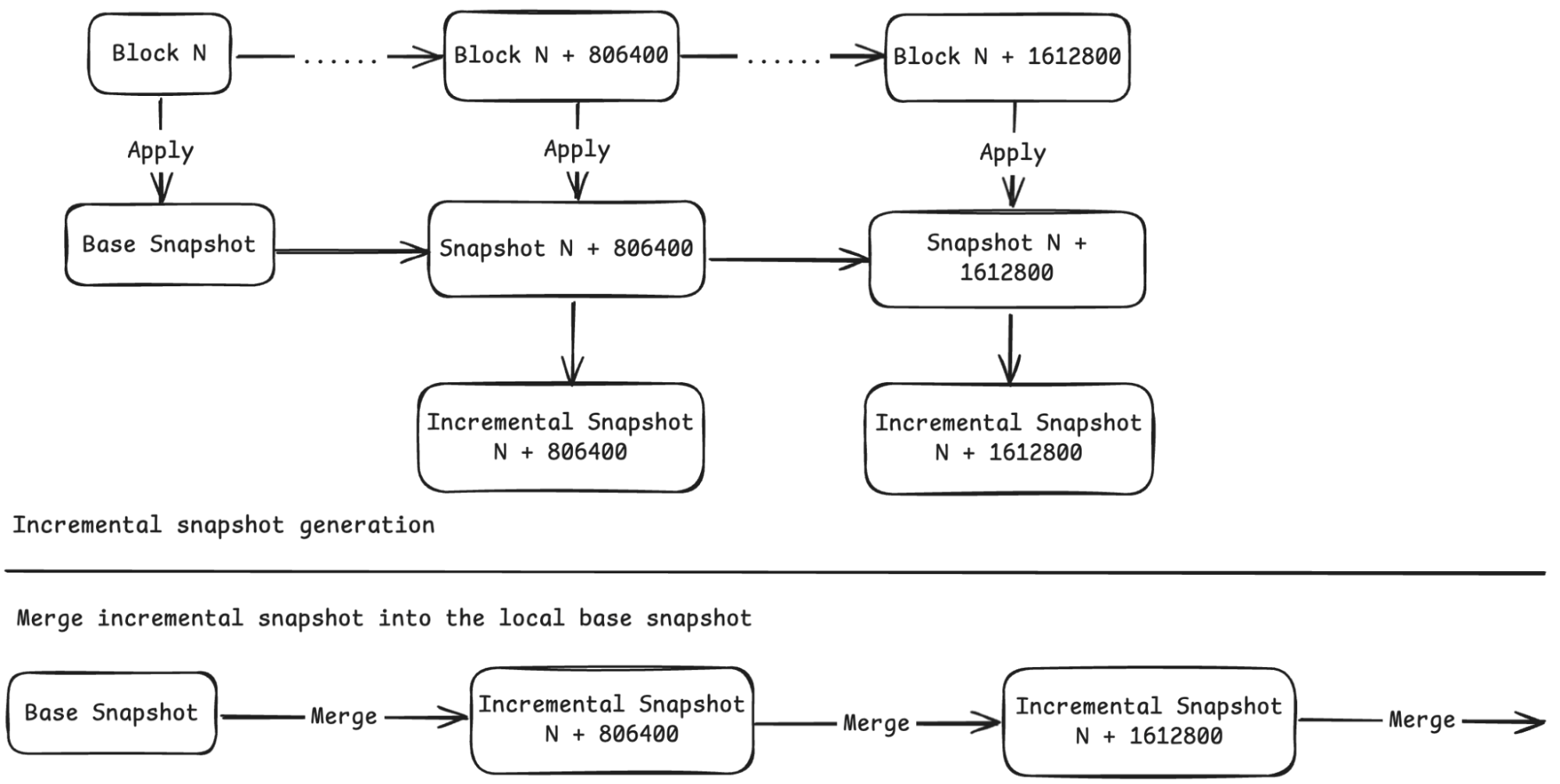
The architecture executes blocks based on a monthly base snapshot, with separate backup of incremental data for each block range. These incremental datasets are periodically aggregated (typically every 806,400 blocks, about 1 week) to maintain optimal size and efficiency.
Data Structure
- Block data:
- block header
- block hash
- block body
- block receipts
- Difficulty
- blob sidecar
- mapping: state id with block number
- empty table: indicates the block has a state transition
- State data
- incr history: store metadata, such as state root, state id range, block range, etc.
- trie nodes: aggregated MPT trie nodes
- snapshot data:account and storage snapshot
Incremental snapshot size optimization strategy
The incremental snapshot solves the massive data volume challenge through strategic pruning and data aggregation:
- Block data: only stores recent thousands of blocks, the default and at least number is 1024 which keeps the smallest block size.
- State data: Aggregated MPT trie nodes and snapshot data in memory to reduce repeated key, values, maintaining monthly size about 120GB
- Weekly incremental snapshot average 30GB, after compressing about 28GB
Incremental Snapshot Generation & Merge
Generation
Users can independently generate incremental snapshots on their own machines. This capability enables organizations to create custom snapshot distribution endpoints or maintain internal snapshots for their infrastructure needs. Generation happens asynchronously during normal node operation with five key configuration flags:
geth --config config.toml --datadir ./data/ --cache 8000 --rpc.allow-unprotected-txs --history.transactions 0 --syncmode full --db.engine=pebble --state.scheme=path --incr.enable --incr.block-interval=806400 --incr.datadir ./incr/ --incr.state-buffer=1073741824 --incr.kept-blocks=1024 --mainnet --history.blocks=360000
- --incr-enable: Activates the incremental snapshot generation engine. When enabled, the node begins creating incremental snapshots alongside normal block processing operations.
- --incr.datadir: Specifies the local directory path where generated incremental snapshots will be stored. This should be a dedicated directory with sufficient storage space for the expected snapshot volumes.
- --incr.block-interval: Defines how many blocks are included in each incremental snapshot package. The default value is 100,000 blocks. When this threshold is reached, the system automatically switches to a new directory and begins generating the next incremental snapshot.
- --incr.state-buffer: Sets the memory buffer size for aggregating MPT (Merkle Patricia Trie) nodes during state data processing. Default is 6GB. To minimize incremental snapshot sizes, configure a larger state buffer. A larger buffer allows the system to aggregate more data in memory, enabling better deduplication and compression of repeated state entries. This results in smaller final snapshot files.
- –incr.kept-blocks: Determines the minimum number of recent blocks to retain in each incremental snapshot. The default and minimum value is 1,024 blocks. This ensures sufficient block history for proper chain validation and rollback operations.
Directory Management and Naming
The system automatically creates new directories when the configured block-interval threshold is reached. Each generated incremental snapshot directory follows the naming convention:
incr-<start_block_number>-<end_block_number>/
For example: incr-50000000-50099999/ contains blocks 50,000,000 to 50,099,999 - incr-50100000-50199999/ contains the next 100,000 blocks. This systematic naming enables easy identification and ordering of incremental snapshots.
Merge Incremental Snapshot
The incremental snapshot merge system provides both automated and manual approaches for consuming snapshots, dramatically improving node startup efficiency and user experience.
Automated Download and Merge
Users can leverage fully automated incremental snapshot consumption through simple configuration:
geth --config config.toml --datadir ./data/ --cache 8000 --rpc.allow-unprotected-txs --history.transactions 0 --syncmode full --db.engine=pebble --state.scheme=path --mainnet --history.blocks=360000 --incr.use-remote --incr.datadir ./store-incr/ --incr.remote-url
https://download.snapshots.bnbchain.world/mainnet-geth-pbss-incr
- --incr.use-remote: Activates the automated incremental snapshot consumption mode. When enabled, the node automatically discovers, downloads, and merges available incremental snapshots from the specified remote source.
- --incr.data-dir: Defines the local directory for storing downloaded incremental snapshots during processing. This directory serves as a temporary workspace for download, extraction, and merge operations.
- --incr.remote-url: Specifies the base URL for incremental snapshot downloads. The official BSC incremental snapshots are available at https://download.snapshots.bnbchain.world/mainnet-geth-pbss-incr. Users can also point to custom snapshot distribution services.
Automated Pipeline Process
The automated merge process operates as an intelligent pipeline that maximizes efficiency:
- Snapshot Discovery: System queries the remote URL to identify available incremental snapshots and determines the optimal download sequence based on the current node state.
- Sequential Download: Incremental snapshots download in chronological order, ensuring proper chain continuity. The system automatically handles network interruptions and resume capabilities.
- Automatic Decompression: Downloaded snapshot archives are automatically extracted to the configured data directory, with integrity verification through cryptographic checksums.
- Parallel Processing: Download and merge operations run concurrently in a pipeline fashion. While one snapshot is being merged, the next snapshot in sequence is simultaneously downloading, dramatically reducing total processing time.
- Database Integration: Both block and state data write directly into PebbleDB using optimized batch operations, bypassing the standard execution validation phases for maximum performance.
- Metadata Synchronization: Critical metadata including HeadHeader, HeadBlock, and chain progression indicators are updated continuously to ensure seamless continuity from the latest merged block.
- Automatic Block Sync Transition: Once all available incremental snapshots are successfully merged, the client automatically switches to full P2P sync mode to continue real-time block synchronization from the network.
This automated approach eliminates manual intervention and provides a seamless zero-configuration experience for users wanting to quickly bootstrap BSC nodes.
Manual Process Workflow
Users download incremental snapshot archives directly from the distribution source or custom URLs using standard download tools. After downloading, Decompress downloaded archives to the designated incremental data directory, maintaining the proper directory structure. Use the merge-incr-snapshot command to merge specific incr snapshots with fine-grained control.
geth snapshot merge-incr-snapshot --datadir ./data/ --state.scheme path --db.engine pebble --incr.datadir ./downloaded_incr/
Compatibility
Incremental snapshot maintains full backward compatibility with existing BSC node implementations. Users have the flexibility to choose between two approaches:
- Traditional full snapshot: Users can continue to use the complete snapshot as before, which contains all historical data.
- Incremental snapshot: Users can opt to use the new incremental snapshot mechanism, which provides smaller, more manageable updates.
Both approaches are supported, ensuring a smooth transition for existing node operators.
Suggestion:
If you want to run an incremental snapshot node and minimize the snapshot size, you need to configure a larger incr.state-buffer. A larger buffer allows better aggregation, merging more duplicate key-value entries. However, this requires significantly more memory. For example, if incr.state-buffer is set to 15GB, the node should have at least 60GB of memory to ensure stable operation.
If you use a pruned snapshot to generate incremental snapshots, the minimum disk requirement will be significantly higher—at least 1.5TB+.
If you intend to make the generated incremental snapshot available to external users, it is recommended to store it on a cloud service such as AWS S3, and provide a publicly accessible download URL. This allows other nodes to quickly fetch the snapshot, improving overall network usability and synchronization efficiency.
Performance Improvements
Storage Efficiency
We used mainnet-geth-pbss-20250605-pruneancient snapshot to generate the incremental snapshot, starting from block height 56,653,252. The generated incremental snapshots data size are as follow:
The chart below highlights the storage size advantage of incremental snapshots compared to traditional full snapshots:
In the full snapshot mode, a new node needs to download the full snapshot(generated on a monthly basis), and to catch up with the latest states. But with the new mechanism of incremental snapshot, which will be generated on a weekly basis, can speed up synchronization dramatically by downloading the incremental snapshot to reduce the synchronization workloads.
Time Efficiency
We use the above generated incremental snapshots to performdo a test, and the used machine specification is m7i.xlarge ec2 machine.
The traditional workflow requires:
- Download: 3 hours for 1TB pruned snapshots
- Decompression: 30 minutes for extraction
- Sync: 36 hours catching up to the current latest block, from 2025/06/05 to 2025/09/04
- Total: 40+ hours minimum
Incremental snapshots enable:
- Initial Download: Base snapshot download (one-time)
- Weekly Updates: total 150GB incremental snapshot downloads in 30 minutes
- Pipeline Download and Merge: Incremental snapshot download and merge time: 1 hour
- Faster Startup: Direct database writes bypass execution validation
Conclusion & Future Work
Incremental snapshots represent a fundamental improvement in BSC node accessibility and operational efficiency. By reducing data requirements by 87% while maintaining full security and compatibility, this innovation removes significant barriers to BSC network participation.
As BSC continues evolving toward higher throughput and broader adoption, incremental snapshots provide the foundation for sustainable, accessible node operation at scale.
Looking ahead, incremental snapshots will evolve toward P2P distribution, making them even more decentralized, resilient, and accessible.
Reference
Incremental snapshot function pre-release: https://github.com/bnb-chain/bsc/releases/tag/v1.6.0-alpha-feature-incr-snapshot