Chains
BNB Beacon Chain
BNB ecosystem’s staking & governance layer
Staking
Earn rewards by securing the network
Build
Explore
Accelerate
Connect
opBNB: High Performance and Low Cost L2 based on Optimism OP Stack

TL;DR:
- The opBNB is a layer 2 solution that enhances the performance and scalability of the BNB Smart Chain (BSC) network. opBNB leverages the Optimism OP Stack Bedrock, an open source modular optimistic rollup framework that is flexible to be modified to meet BSC ecosystem requirements.
- Layer 1 networks, such as BSC and Ethereum, often face challenges such as high gas fees and network congestion that can affect the performance and scalability of large scale applications. opBNB is a project that aims to address these issues in the BNB ecosystem by providing a fast, secure and low-cost solution for developers and users.
- By introducing the optimizations on the OP Stack, including the optimizations of execution, mining process and batcher, opBNB can reach the capacity of 4000+ TPS and 1 second block time with transaction fee lower than $0.005 for transfer transactions.
- By implementing these optimizations, we aim to create value for both the BNB ecosystem and the optimistic rollup community. Our contributions to the Optimism OP Stack reflect our dedication to the development of the layer 2 ecosystem.
Why does BSC need a new L2?
Layer 1 networks are the base networks that provide the infrastructure for data transmission and validation, such as BSC and Ethereum. These networks face the challenge of network congestion during peak periods, which usually happens when any popular application runs a promotion campaign or experiences a spike in traffic. Network congestion can lead to high transaction fees, slow transactions, and poor user experience.
To overcome these challenges, layer 1 networks need to improve their scalability, which is the ability to handle more transactions per second without compromising security. For example, BSC had a web3 game on BNB Smart Chain (BSC) in 2021 which generated over 8 million transactions per day.

1. BSC's throughput capacity would presumably be vastly exceeded, resulting in slowed transaction speeds, delayed transaction finality, and a poor user experience both for game players and users of other dApps.
2. Daily gas fees could potentially rise to over 6,800 BNB ($3M USD) at that level of usage, posing a substantial barrier to usability and sustainability of this game.
The immense transaction loads from a dApp on such a large scale seem infeasible for BSC to handle efficiently in its current form. Significant optimizations and scaling solutions would likely be required for BSC to support such a dApp without network-wide performance degradation and unreasonably high costs.
Why choose OP Stack as foundation of opBNB?
The opBNB network is a Layer 2 scaling solution built on top of the BSC based on OP Stack.
The OP Stack is a framework for building scalable and interoperable layer-2 solutions based on the utility, simplicity and extensibility principles. By choosing OP Stack as the foundation of opBNB, opBNB can achieve several benefits, such as:
- Modularized frameworks: opBNB can customize most of the modules, such as a flexible execution client for performance optimization, replacing a different data accessible layer for data scalability enhancement, adopting various types of proof generation(including zk proof) logic, and etc.
- Open ecosystem: OP Stack also fosters an open and collaborative ecosystem where different projects can work together and benefit from each other. By using OP Stack, opBNB has joined a network of layer 2 chains that share the same tech stack and interoperate with each other.
- Contributing to the optimism of OP Stack: BNB Chain Community respects all the efforts and innovations introduced by Optimism to the OP Stack framework. The optimisations and innovations adopted by the opBNB can also benefit the ecosystem, therefore will be contributed to the OP Stack to boost the development of optimistic rollup for the whole industry.
How does opBNB achieve high performance and cheap gas fees?
opBNB testnet enhances the performance of the “Execution Layer” and the “Derivation Layer” of the OP Stack as highlighted in OP Stack landscape.
Optimization of Execution Layer
One of the main challenges in developing the opBNB protocol was to ensure a high throughput of transactions. To achieve this, opBNB leveraged execution optimization techniques that had previously been implemented for BSC.
EVM State Data Access Optimization
Before we dive into the details of the optimisations, let's see how EVM handles the state data. The diagram below illustrates how the EVM accesses state data. The EVM first checks the cache in memory for the data. If the data is not there, the EVM uses the LevelDB, which involves disk IO.
By improving cache efficiency and accelerating database reads and writes, opBNB realizes substantial performance and scalability gains that benefit both node operators and end users.
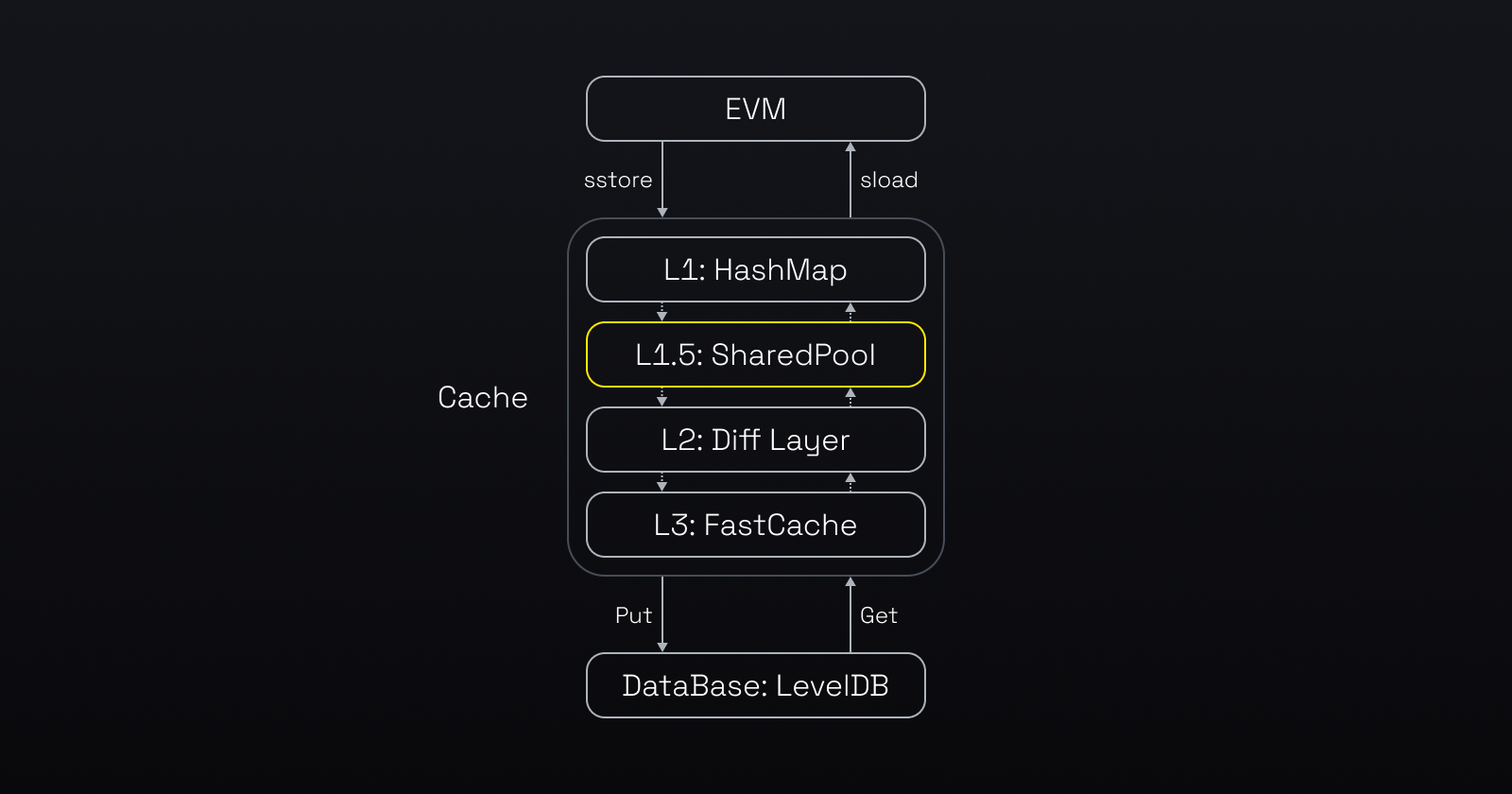
(Compared with standard Ethereum world state data storage model, BNB introduced the “SharedPool” as L1.5 cache to improve the hit rate of cache)
Avoid unnecessary recursive accesses to cache by increasing the accuracy of Bloom Filter in L2: Diff Layer
Bloom filters are a probabilistic data structure that can rapidly verify if an element exists within a data set. To access the state data, EVM uses the bloom filter to verify if the key-value pair is in the Diff Layer and then searches the cache recursively until it finds them, otherwise, EVM directly reads the data from the levelDB.
However, bloom filters may yield false positives. Moreover, the rate of false positives increases as the dataset bloom filters evaluate expands. Given the opBNB dataset is larger than Ethereum's, the potential for false positives could be greater as well.
The false positive can result in the unnecessary recursive access. To mitigate this, opBNB reduced the diff layer level from the default of 128 to a configurable parameter set at 32. This reduction decreases the size of the dataset, in turn diminishing the possibility of false positives to avoid the unnecessary time consuming operations to increase the efficiency of state retrieval.
Make Prefetch more effective in the cache model of L1.5 and its upper layers
Prefetch is a technique that enhances the performance of transaction execution by loading data from disk to cache in advance. When a block needs to be processed in full sync mode or mined in mining mode, the opBNB node launches N threads to perform state prefetch.
The threads execute the transactions of a block or TxPool and discard the results, but keep the data items in the cache. This way, when the node needs to access the data, it is more likely to find it in the cache rather than on disk, which improves the cache hit rate.
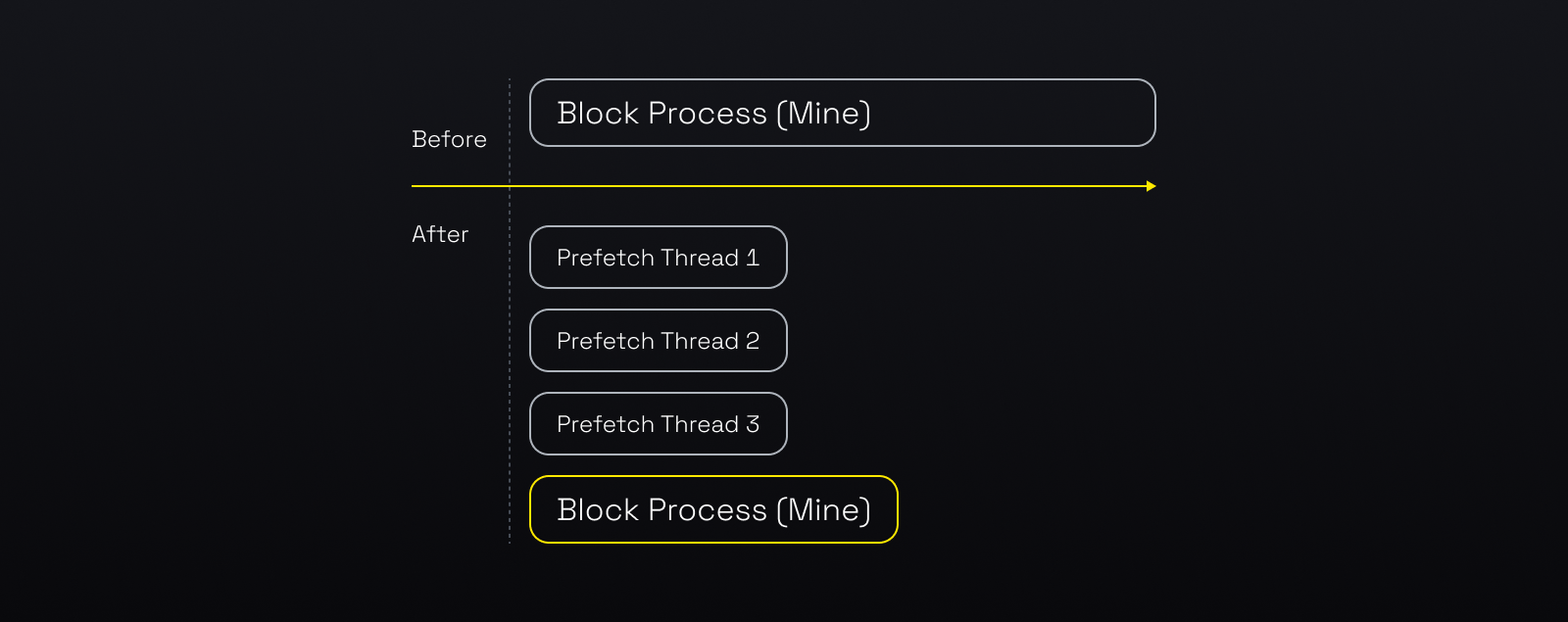
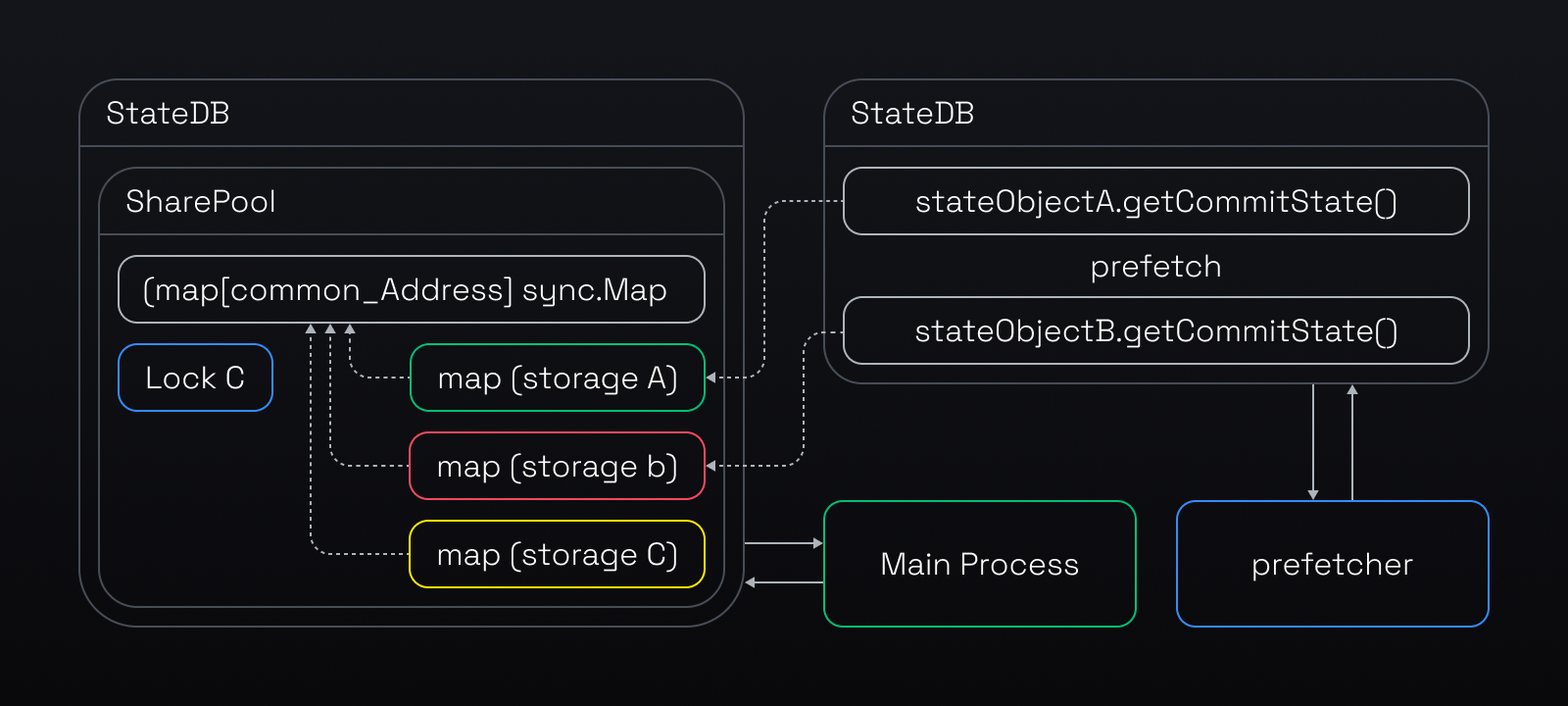
However, the original prefetch design had a performance limitation. It used separate state databases for the prefetch and the main processes. The prefetch threads could only store the prefetched data in the L2 diff layer (See the 3 layer cache model that was explained before). To access this data, the main process had to traverse the L1, L2, and probably L3 layers, which was too slow for a high performance layer 2 chain.
The new design improves performance by sharing a pool that holds the whole world state (originStorage) between the prefetch and the main EVM processes. This way, the prefetch threads can put the prefetched data right into the L1.5 (the upper layer of the cache model), which makes it faster for the main process to access. See the detailed process below.
Mining Process Optimization
The process of mining L2 blocks of OP Stack is illustrated in the diagram. It involves a loop where the Rollup Driver (opNode) imports the previous blocks and then invokes the Engine API (op-geth) to produce new blocks on Layer 2.
{kind=link}
The Rollup Driver (opNode) initiates the block generation process on op-geth by calling the engine_forkChoiceUpdatedv1 API of the Engine API(op-geth). This instructs Engine API(op-geth) to start producing an initial block by executing the transactions. (See “Engine API: Initiate block production” in the diagram). The Engine API(op-geth) then returns a payload ID to the Rollup Driver (opNode).
However, when Engine API(op-geth) receives the engine_newPayloadV1 call from the Rollup Driver (opNode) to commit the block, it has to execute the transactions again, which is redundant and time-consuming. It can take hundreds of milliseconds to complete.
To optimize the performance, we added a cache layer to store the execution results during the initial block production step. This way, when op-geth receives the engine_newPayloadV1 call, it can retrieve the data from the cache instead of executing the transactions again. This saves time and resources for the system.
Optimization of Derivation Layer
The batcher performance bottleneck was caused by the need to wait for 15 blocks (45 seconds) on Layer 1 (BSC) to confirm each batch of transactions before submitting the next one. This was due to the possibility of reorg on Layer 1 chain. To solve this problem, we introduced the asynchronous submission feature, which allows the batcher to submit batches without waiting for confirmation.
A separate monitor process keeps track of Layer 1 and notifies the batcher if a reorg happens, so that the batcher can resubmit the affected transactions. This feature improves the efficiency of the batcher. It is not yet available on testnet and is still under development, but it will be deployed on opBNB mainnet.
Contribute Back to Open Source Community
OpBNB utilizes the robust and adaptable OPStack framework, which allows for quicker and simpler deployment of scalable Layer 2 infrastructure. These major optimizations applied to the opBNB are advantageous not only for the BNB Chain community but also for the broader Layer 2 open-source ecosystem. Here are some examples that have already been submitted to the OP Stack.
Eliminate the addSafeAttributes Function
Abort Failed Payload Confirmation
opBNB codebase is fully open source and all the optimizations in opBNB can be reused in other optimistic rollup implementations as well. We hope that this work will inspire more collaboration and innovation among EVM-compatible blockchain developers and users.
Looking Forward
OpBNB is part of BNB Chain's wider vision on mass adoption and focusing on the user experiences: high performance, cheaper and secure blockchain ecosystem. opBNB testnet is just the beginning. opBNB will keep optimizing the OP Stack on different modules, including replacing a different data accessible layer by BNB Greenfield for data scalability enhancement, adopting various types of proof generation by zk proof, and etc.
All developers and projects are invited to experiment with opBNB testnet. Whether you are looking to build a high-volume decentralized application, gaming platform or a social network, opBNB offers an ideal environment for your creativity to flourish. Your contribution will not only benefit your project but also contribute to the broader BSC and L2 ecosystem
Follow us to stay updated on everything BNB Chain!
Website | Twitter | Twitter (Devs) | Telegram | dApp Store | YouTube | Discord | LinkedIn | Build N' Build Forum | Dev Community|