Chains
BNB Beacon Chain
BNB ecosystem’s staking & governance layer
Staking
Earn rewards by securing the network
Build
Explore
Accelerate
Connect
Optimized Interpreter: Design and Performance Analysis

TLDR:
The Optimized/MIR (Mid-level Intermediate Representation) Interpreter is an optimized EVM execution engine that transforms stack-based EVM bytecode into a register-based Control Flow Graph (CFG) representation. This design enables significant performance improvements for real-world smart contracts (8-27% faster) while maintaining 100% compatibility with EVM semantics. To further boost performance, BNB Chain is realigning its benchmark and implementing this new design, for implementation details of the POC, you can find it in BNBChain github repo.
1. Architecture Overview
1.1 Stack Based Interpreter Design
The standard stack-based interpreter suffers from a major performance bottleneck caused by the lack of preprocessing, which forces the engine to execute bytecode "naively" without prior analysis. Because it treats every instruction as if it is being encountered for the first time, the interpreter is locked into a repetitive and costly fetch-decode-execute cycle, consuming significant CPU resources on administrative tasks like opcode dispatching, dynamic jump destination verification, and redundant stack shuffling (PUSH/POP operations).
This overhead becomes particularly punishing in loops, where the engine must re-validate the same instructions and bounds checks thousands of times, resulting in a system where more time is often spent managing the execution environment than executing the actual smart contract logic.
1.2 MIR based optimized EVM interpreter Design Philosophy
The optimized EVM interpreter takes a compile-time optimization approach:
- Static Analysis: Analyzes bytecode at contract deployment/load time
- CFG Construction: Builds a Control Flow Graph with basic blocks
- Register-Based IR: Converts stack operations to register-based SSA-like representation
- Runtime Execution: Executes optimized CFG instead of raw bytecode
- Cache: Executed CFG will be cached for contracts.
2. Detailed Design Comparison
The transition from a native Stack-Based Interpreter to a Register-Based MIR (Middle Intermediate Representation) Interpreter represents a shift from simple, sequential instruction processing to a sophisticated, ahead-of-time optimized execution model. While the native EVM suffers from high per-opcode overhead due to constant stack manipulation ($PUSH$, $POP$, $DUP$) and repetitive gas/stack-depth calculations, the MIR design utilizes Control Flow Graphs (CFGs) and Basic Blocks to pre-analyze code structure.
By replacing the physical stack with a virtual register file and implementing a multi-level Value Resolution Algorithm the optimized interpreter eliminates redundant operations and enables cross-block value reuse, significantly improving execution throughput and efficiency.
2.1 Execution Model
Stacked based (native EVM) Interpreter
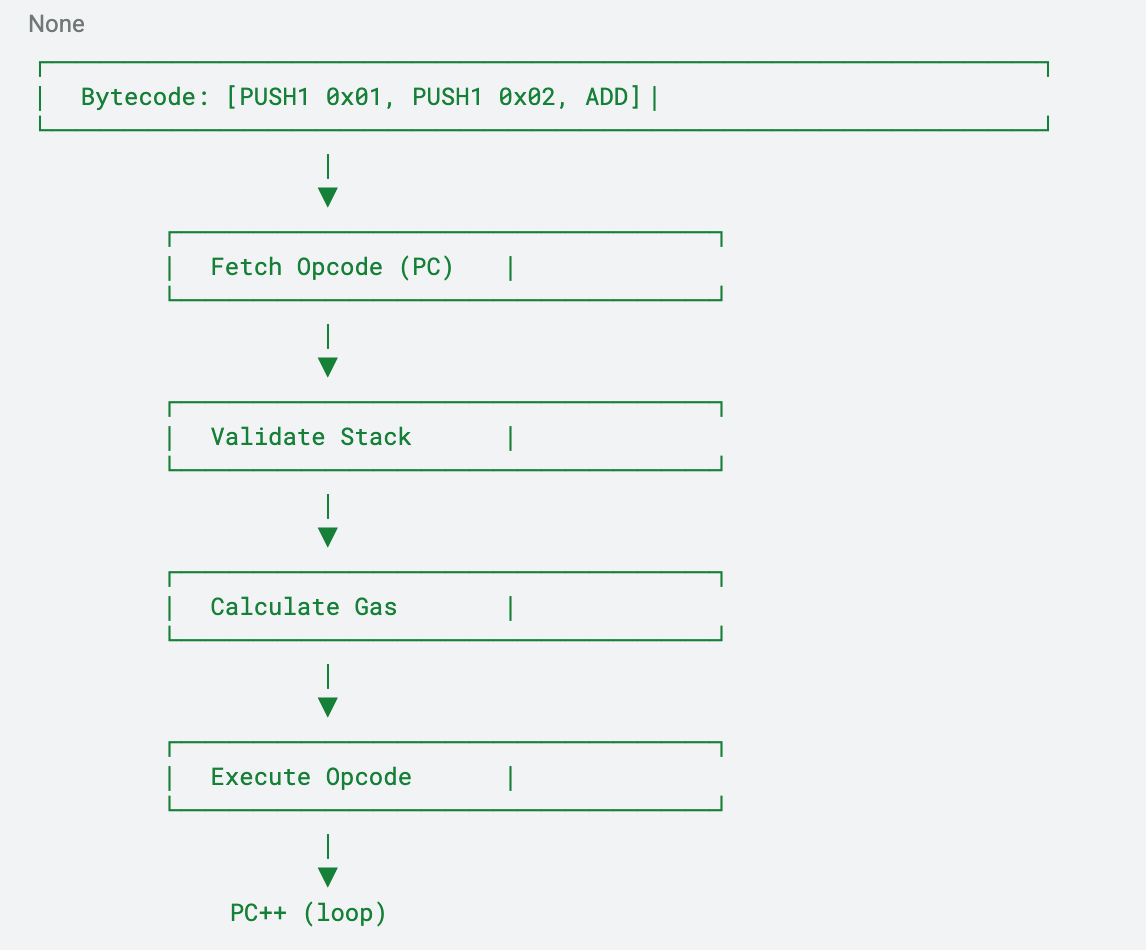
Characteristics:
- Sequential bytecode traversal
- Per-instruction overhead (stack checks, gas, dispatch)
- No cross-instruction optimization
- Simple but repetitive execution loop
Optimized/MIR Interpreter
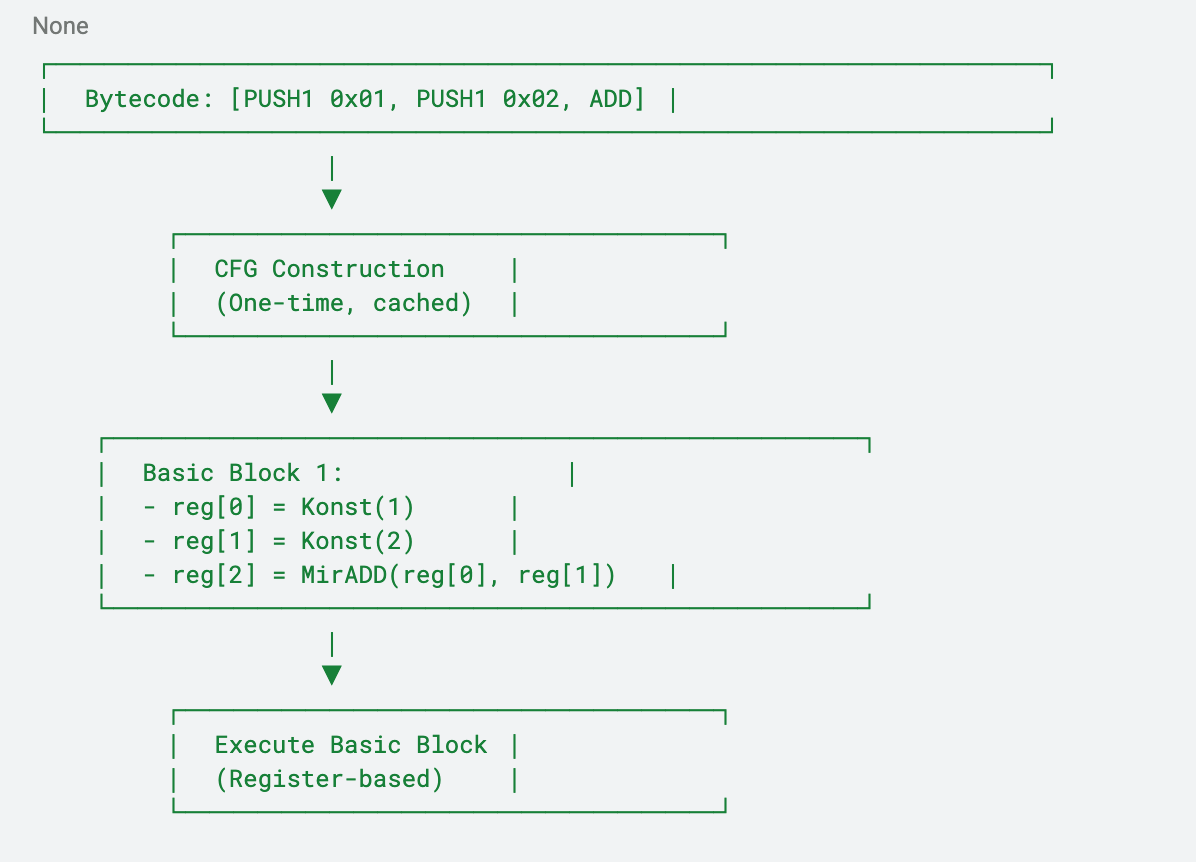
Characteristics:
- Pre-analyzed CFG structure
- Register-based value storage
- Cross-block value resolution
- Optimized execution paths
2.2 Value Storage and Resolution
Stack-Based

Limitations:
- Stack depth checks on every operation
- No direct value reuse across instructions
- Stack manipulation overhead (DUP, SWAP, POP)
Register-Based with Global Caches

Advantages:
- Direct register access (no stack manipulation)
- Cross-block value reuse via caches
- PHI nodes for control flow merge points
- Signature-based caching for loop handling
2.3 Control Flow Handling
Control Flow is the order of execution for instructions in a program. Sequential execution, conditional branch and loop are some basic control flow patterns.
Stack based: Linear with Dynamic Jumps

Characteristics:
- PC-based jump resolution at runtime
- No control flow analysis
- Each jump requires runtime validation
MIR: CFG-Based with Pre-computed Basic Blocks (structure explained in section 2.4)

Advantages:
- Pre-validated jump targets
- Basic block-level execution
- Optimized block transitions
- Live-in/live-out analysis
2.4 Basic Block Structure
A Basic Block is a straight-line sequence of instructions with no branches or jumps. It guarantees a single entry point, a single exit point and linear execution.
MIR Basic Block
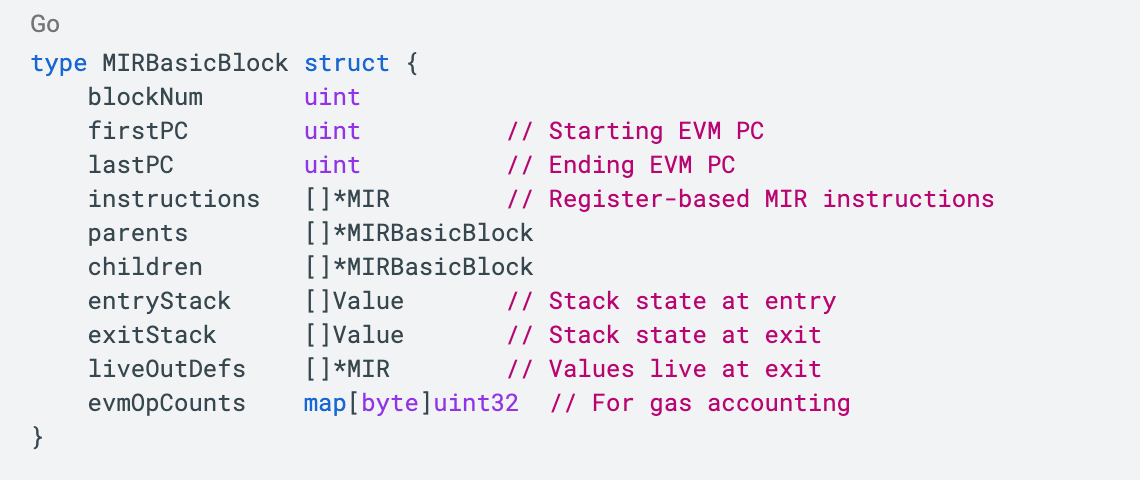
Key Features:
- Single entry, single exit (except terminal blocks)
- PHI nodes at merge points (multiple parents)
- Live-in/live-out analysis for value resolution
- Pre-computed stack states
2.5 Value Resolution Algorithm
MIR uses a sophisticated multi-level value resolution:

Resolution Strategy:
- Local First: Check if value is in current block's register file
- PHI Handling: Use predecessor-specific values for merge points
- Global Cache: Check signature-based cache (evmPC + idx) for cross-block values
- Fallback: Use pointer-based cache or return zero
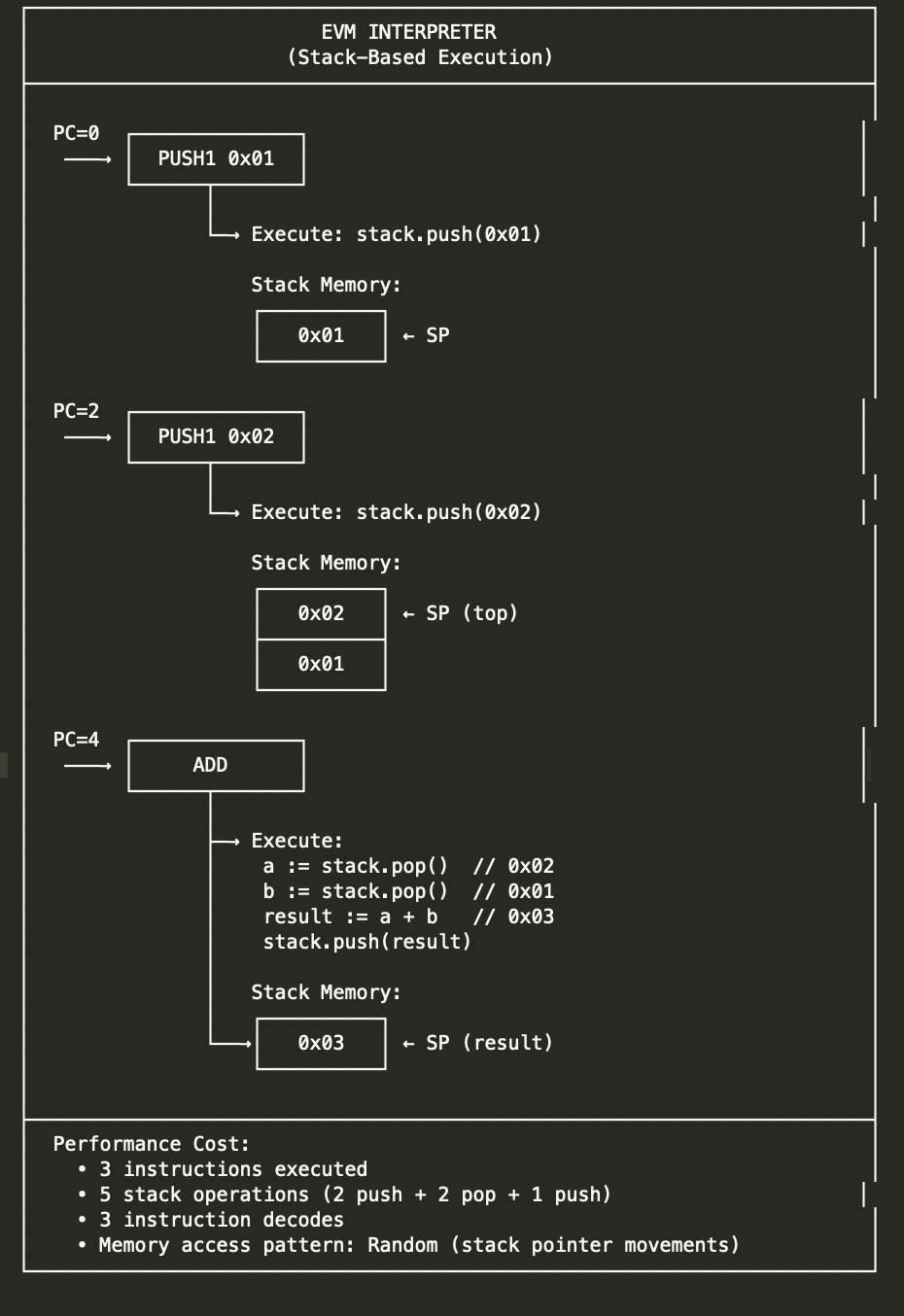
2.6 memory mode examples
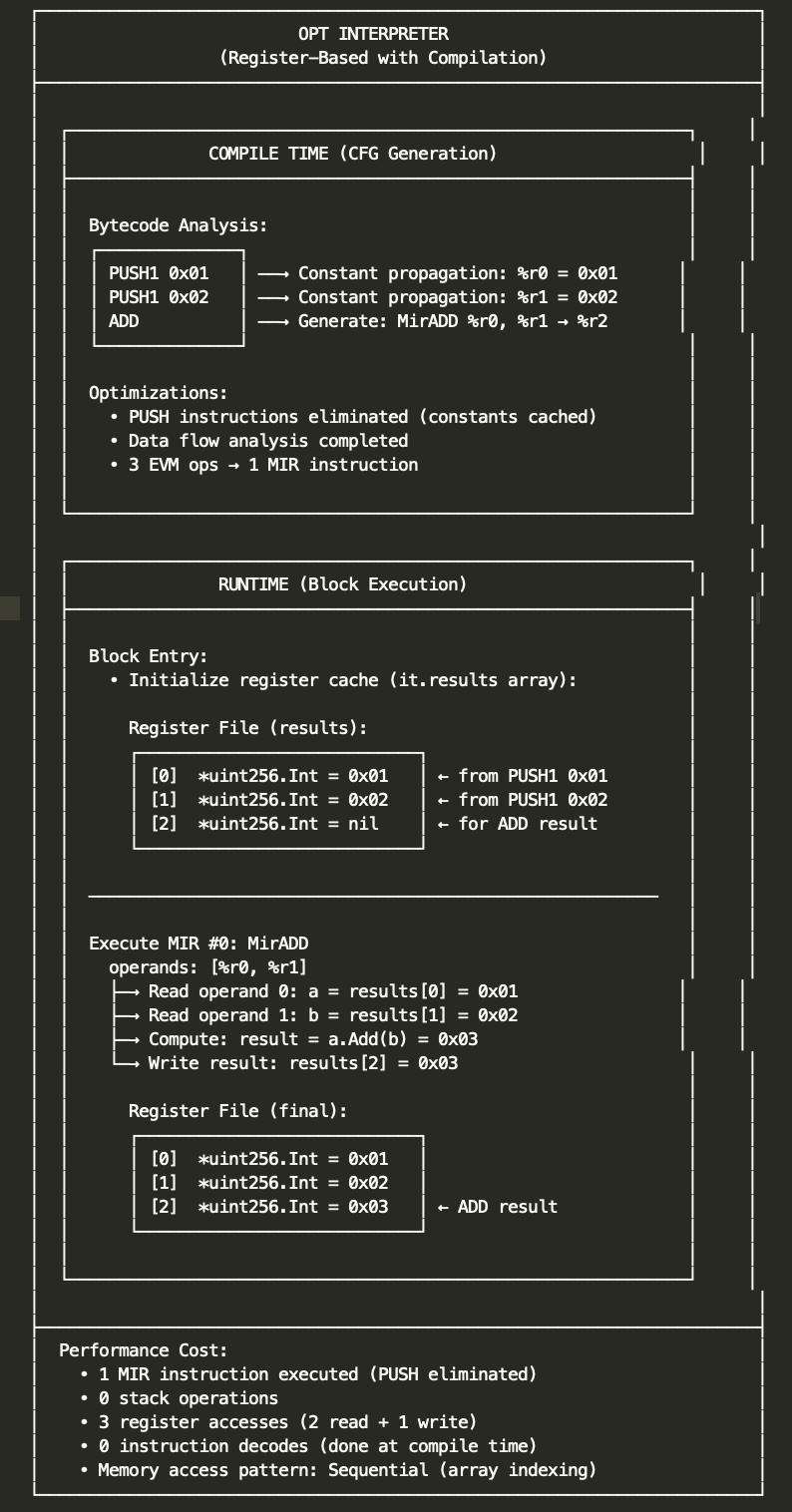
3. Key Design Differences
3.1 Stack Based Interpreter vs Optimized Interpreter
3.2 Memory Model
3.3 Error Handling
4. Performance Analysis
4.1 Benchmark Results Summary
Simple Operations (CFG Overhead)
Analysis: MIR has fixed CFG construction overhead that dominates for trivial operations.
USDT Contract (Average: ~11% faster)
WBNB Contract as an example (Average: ~23% faster)
4.2 Performance Characteristics
When MIR is Slower
- Very simple operations: CFG construction overhead dominates
- One-time execution: CFG cache not amortized
- Trivial contracts: Overhead exceeds optimization benefits
When MIR is Faster
- Complex contracts: CFG overhead amortized across many instructions
- Repeated execution: CFG cached and reused
- Real-world contracts: 8-27% performance improvement
- Loops: Value caching reduces redundant computation
In summary, optInterpreter's advantage lies in its upfront investment model: once a contract is initialized and compiled, all subsequent executions become faster. This makes it particularly powerful for frequently-executed contracts, where the compilation cost is amortized across many calls.
4.3 Performance Scaling
The performance advantage of MIR increases with contract complexity:

Key Insight: The CFG construction cost is fixed, but optimization benefits scale with code complexity.
5. Implementation Details
POC code here: https://github.com/bnb-chain/bsc/tree/MIR-interp-develop
5.1 CFG Construction

Process:
- Start with entry block at PC 0
- Process bytecode sequentially
- Create new blocks at JUMPDEST, JUMP, JUMPI
- Build parent-child relationships
- Insert PHI nodes at merge points
- Analyze live-in/live-out values
5.2 Execution Flow

Execution Steps:
- Retrieve cached CFG (or build if not cached)
- Resolve entry block (function selector or PC 0)
- Execute basic blocks in CFG order
- Handle jumps via block transitions
- Resolve values via multi-level cache
5.3 Gas Metering Integration
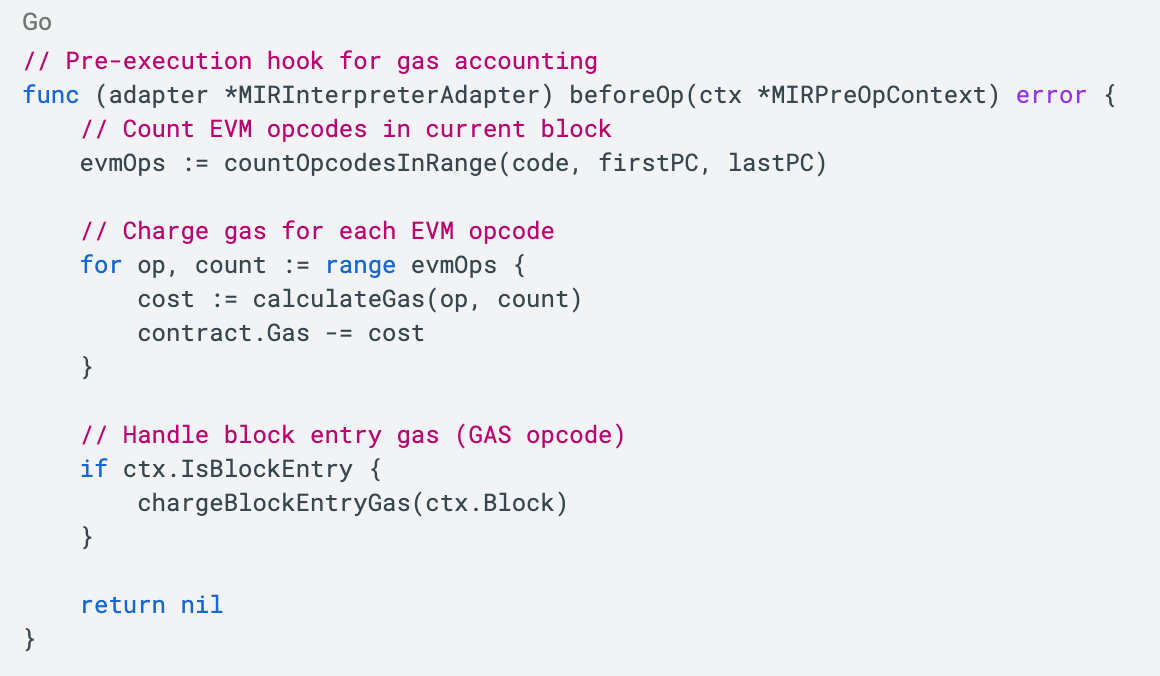
Key Features:
- Gas calculated per basic block (not per MIR instruction)
- EVM opcode parity maintained
- Block entry gas handled separately
- Compatible with EVM gas semantics
6. Advantages and Limitations
The MIR interpreter's primary strength is its amortized efficiency. Because the CFG is cached, the analysis cost is paid once, while performance gains of 8–27% are realized on every subsequent execution. However, this design introduces a "cold start" penalty where rarely used or extremely simple contracts might execute slower than they would on a native stack-based interpreter due to the initial CFG construction time and higher memory footprint.
Comparison: Advantages vs. Limitations
7. Conclusion
The OPT Interpreter represents a compile-time optimization approach to EVM execution. By transforming stack-based bytecode into a register-based CFG, MIR achieves significant performance improvements (8-27%) for real-world smart contracts while maintaining full EVM compatibility.
Key Takeaways:
- Design: Register-based CFG vs stack-based linear execution
- Performance: 8-27% faster for production contracts
- Trade-off: CFG overhead for simple code, optimization benefits for complex code
- Scalability: Performance advantage increases with contract complexity
- Compatibility: 100% EVM semantic parity maintained
The MIR design is particularly well-suited for production environments where contracts are executed repeatedly, allowing the CFG construction cost to be amortized and optimization benefits to compound.