Chains
BNB Beacon Chain
BNB ecosystem’s staking & governance layer
Staking
Earn rewards by securing the network
Build
Explore
Accelerate
Connect
Scalable DB: The Next Step in BNB Smart Chain’s Data Architecture

TL;DR
- BNB Smart Chain’s on-chain state has grown over 30× faster than Ethereum, reaching 3.43TB by May 2025.
- To prepare for future growth, BSC introduces Scalable DB, a horizontally scalable multi-database storage model.
- BSC has researched state expiry in detail (see: github.com/bnb-chain/BSC-State-Expiry) but has paused implementation due to performance trade-offs.
- The new architecture splits storage across multiple databases and adds state sharding, improving I/O throughput and parallelism.
- Benchmarks show up to 75% faster write performance and 12% better read performance under multi-threading.
- Scalable DB ensures stable, efficient, and high-performance storage as the BSC ecosystem continues to expand.
Background
State growth is one of the biggest challenges facing blockchains today. For a high-throughput network like BNB Smart Chain (BSC), that challenge compounds quickly.
As one of the industry’s most active networks, BSC’s state has expanded more than 30× faster than Ethereum.
Between January 2024 and May 2025, the full node snapshot grew from 2.45TB to 3.43TB.
This 3.43TB of storage is split roughly as follows:
- Block data (≈ 2/3) - block headers, bodies, and receipts
- World state (≈ 1/3) - account state and key/value (KV) storage data
As BSC’s popularity grew, the rate of state expansion tripled. Including block data, the total state size is projected to reach 2.5–3.0 TiB within three years.
To handle this growth without compromising performance, BSC has developed Scalable DB — a storage model that maintains high throughput under massive data loads and sets the foundation for parallel blockchain execution.
In short, Scalable DB is how BSC stays fast as the chain (and its data) keep growing.
Why Not State Expiry For Now
State expiry is often proposed as a solution to blockchain state explosion, and BSC has conducted detailed research on it through the BSC-State-Expiry initiative.
The concept is based on EpochMap metadata, which tracks state access history. If a trie node hasn’t been accessed for two Epochs, it can be pruned. This model also includes a Rent System that records rent balances at the account level, allowing contracts to remain exempt from expiration.
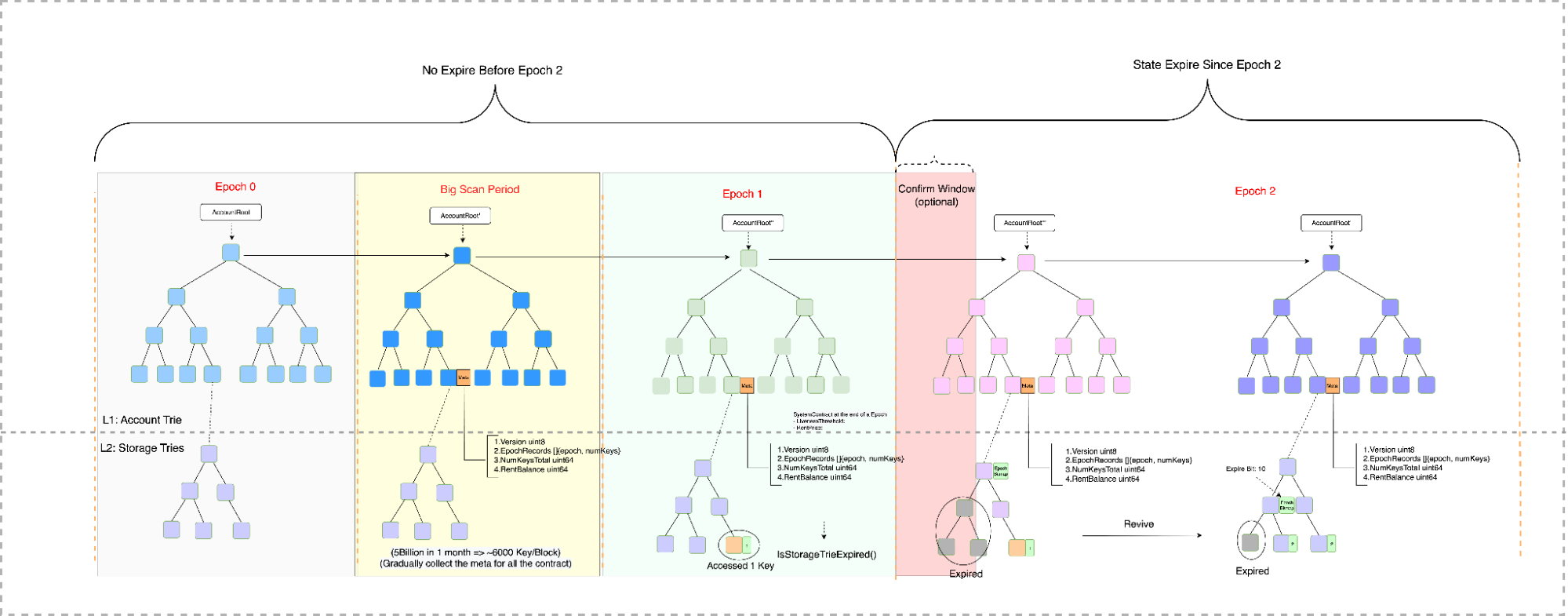
A prototype was implemented to trim expired states using EpochMap metadata, while expired data could still be accessed via RemoteDB for mining and syncing.
However, internal benchmarks revealed significant performance overhead. Instead, the focus has shifted to scaling the data layer itself through Scalable DB.
Given BSC’s current focus on throughput, reliability, and sustained network performance, state expiry will be revisited in the future, but it is not the optimal solution at this stage.
SingleDB Problems
Without state expiry, the growing on-chain data volume creates pressure on the single-database design of the current BSC client.
Currently, all BSC node data (excluding ancient archives) is stored in a single PebbleDB instance, where key prefixes distinguish data types.
As data expands, this approach encounters several limitations:
- Compaction Overhead - LSM tree compaction grows super-linearly with size, slowing reads and introducing latency spikes.
- Write Stalls - Write amplification and compaction debt can stall writes, directly harming block production.
- Inflexibility - Database parameters cannot be customized for different data types, limiting optimization for varied workloads.
To overcome these bottlenecks, BSC engineers began redesigning the data layer for horizontal scalability.
Path to Scalable DB Through Multi-DB Design
BSC will adopt a multi-database architecture combined with state sharding, providing horizontal scalability and consistent high performance.
Multi-DB Structure
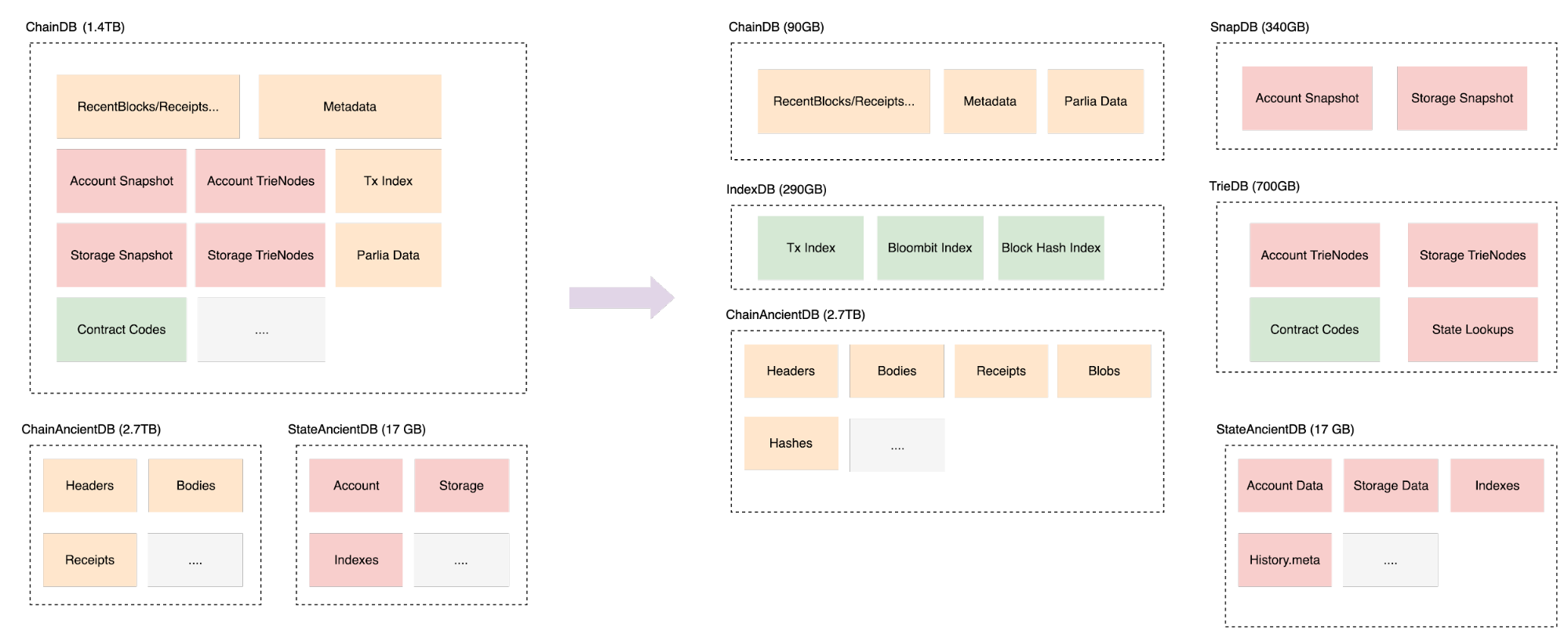
The BSC client will divide storage into multiple databases. This separation isolates read/write operations, improves parallelism, and enables fine-tuned performance for each data type.
ChainDB
Handles recent blocks, reorg logic, consensus data, and chain metadata.
ChainAncientDB
Stores archived block data, which is reorg-proof and used for full sync or historical data retrieval.
IndexDB
Holds historical transaction indexes, such as the TransactionIndex (277GB and growing).
Because deletion requires scanning historical data, future versions may make this optional, allowing IndexDB to be removed entirely.
SnapDB
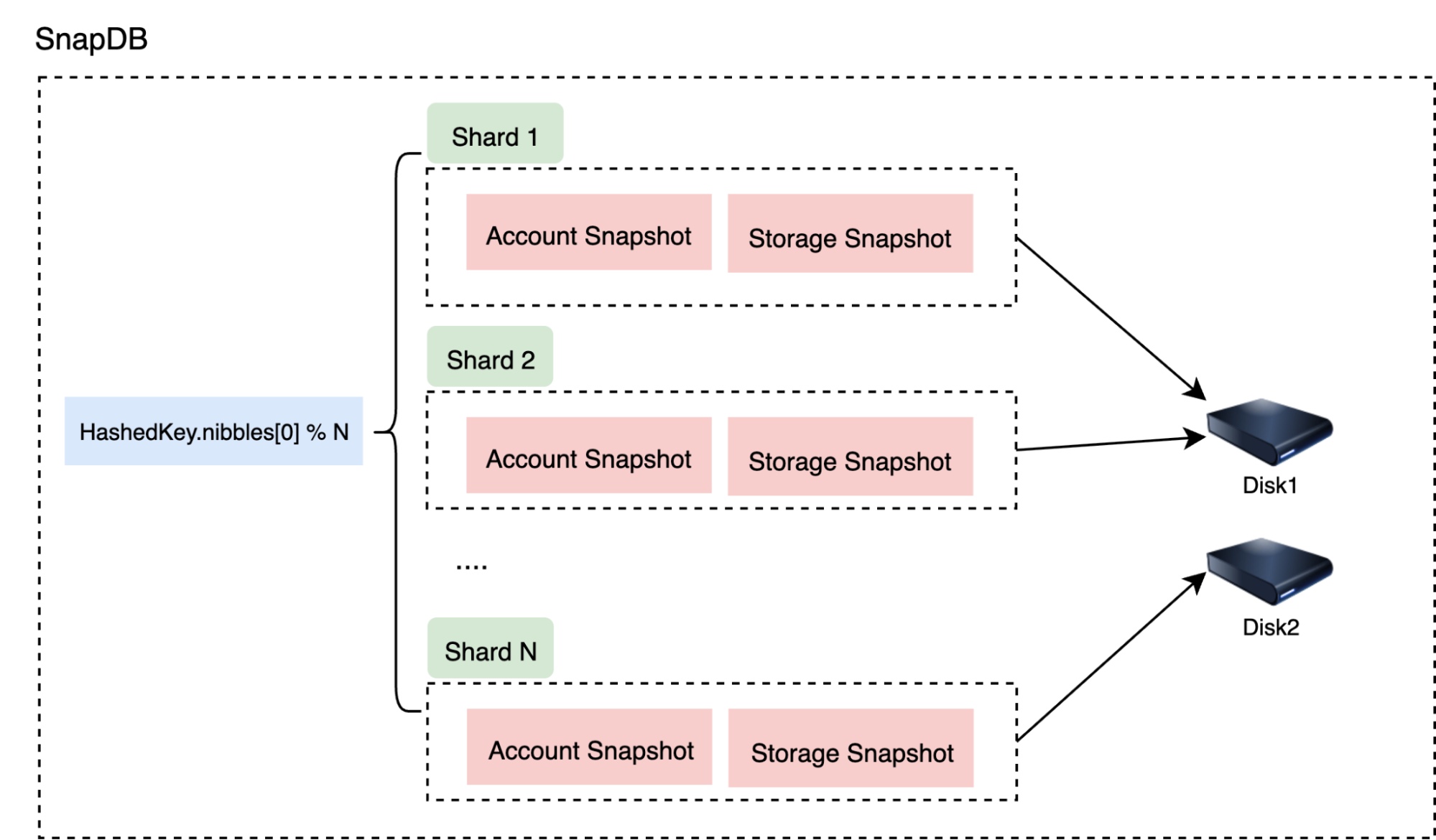
Stores flattened state data (including snap journals and metadata) derived from TrieDB for faster state queries in the EVM.
Reducing the LSM tree depth improves I/O efficiency—experiments show a ~5% reduction in read latency on NVMe disks when SnapDB size reaches ~1.5 TiB.
TrieDB
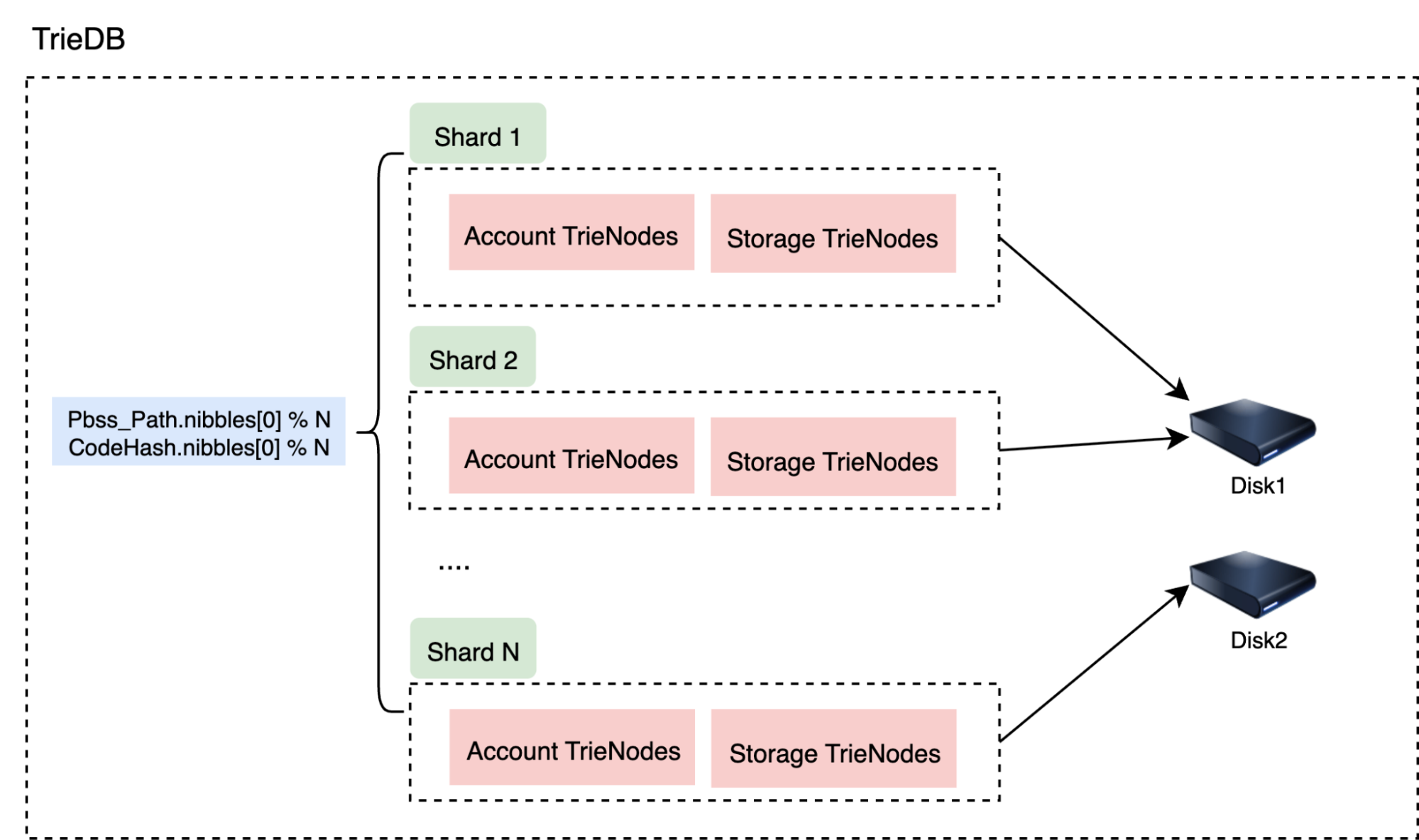
Contains the complete world state trie, following the PBSS schema format.
Contract code is also stored here, with average key-value sizes of ~8KB.
Trie nodes undergo frequent overwrites along ordered paths, making compaction costly if stored alongside hashed data.
By separating TrieDB, compaction becomes simpler, reducing latency and improving database efficiency.
StateAncientDB
Preserves the historical state of PBSS for exception handling and data recovery, storing the state history of the most recent 360,000 blocks.
Together, these databases distribute workload evenly, reduce contention, and provide a foundation for future scalability.
State Sharding
On top of the multi-DB structure, BSC will introduce state sharding for both SnapDB and TrieDB.
This approach distributes data horizontally, significantly improving write performance and overall scalability.
Each shard will rely on its own disk, enhancing I/O throughput and reducing compaction pressure.
SnapDB Sharding
Account keys are generated from hash(address) and storage keys from hash(slot), creating uniformly distributed 256-bit keys.
This allows a sharding algorithm to evenly distribute state data across shards.
TrieDB Sharding
Trie nodes stored using PBSS can be efficiently sharded based on trie paths.
Because trie paths are evenly distributed, this approach ensures balanced data distribution and optimal I/O performance.
This ensures that even as the state grows exponentially, performance scales linearly.
Data Consistency
Ensuring consistency across shards is a classic distributed systems challenge.
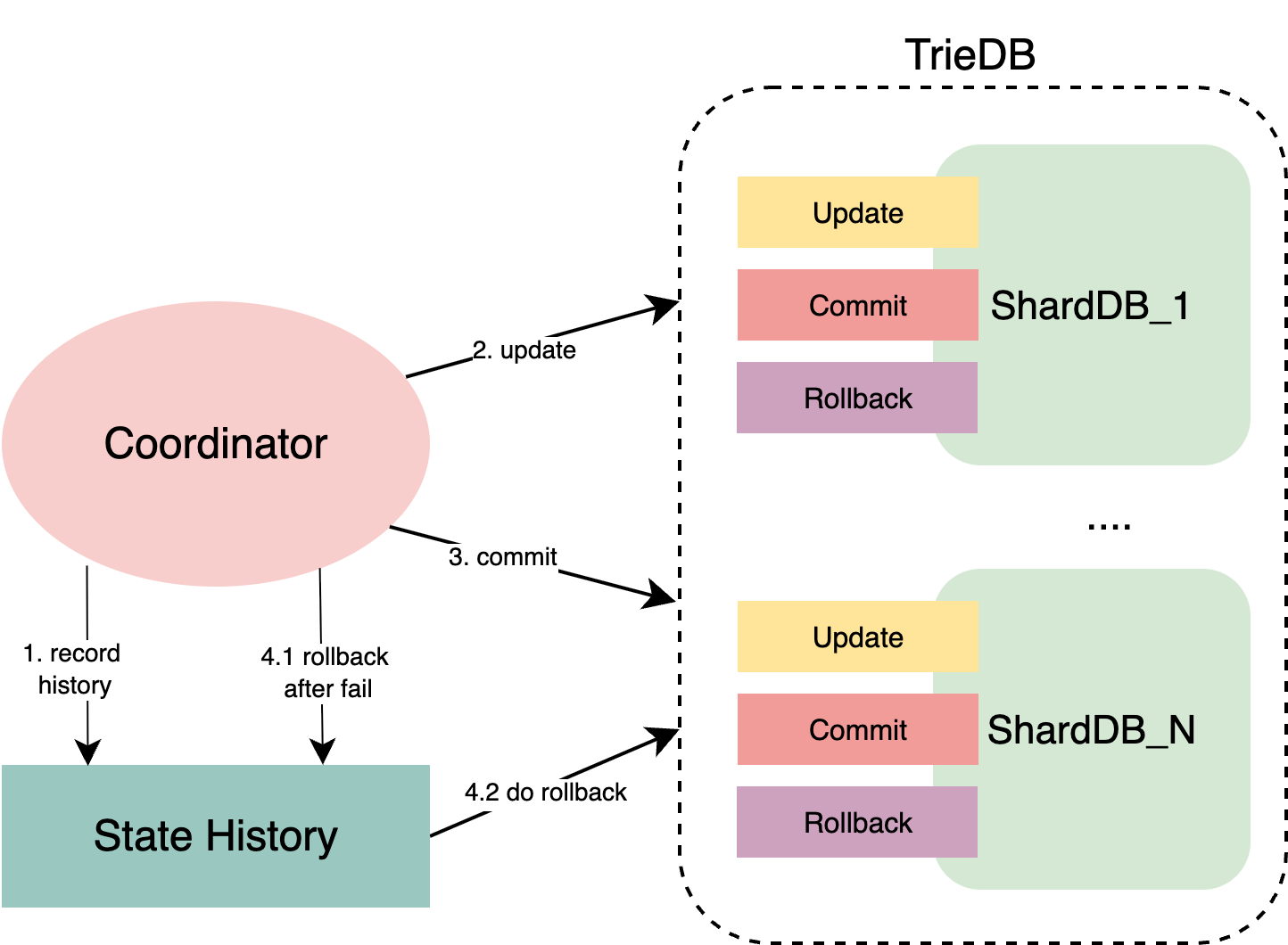
BSC addresses this using a Saga-based distributed transaction approach.
When data is submitted to ShardingDB:
- State history is written first.
- Updates are applied to each shard.
- If any update fails, all changes are rolled back using history data.
- If the commit fails, it is similarly rolled back to maintain integrity.
This guarantees all-or-nothing transactions and ensures data consistency even after failure recovery.
Parallelization Optimization
In the current BSC client, the state and trie prefetchers already execute transactions in parallel by caching state data.
With state sharding, these reads and writes can now occur concurrently across shards.
Multiple threads can submit state and trie updates to different shards in parallel, collecting write results after execution, which significantly improves total throughput.
Shared Cache
Because Scalable DB involves multiple databases, memory management becomes critical.
By implementing a shared cache mechanism, BSC improves resource utilization across all databases.
This optimization allows block caches, filter caches, and index caches to be shared between shards, offering significantly better read/write performance compared to isolated memory allocation.
In essence, Scalable DB uses memory more intelligently, every byte serves multiple databases.
DB Benchmark
To validate Scalable DB, the team benchmarked the new architecture against the traditional single-DB setup.
Test Setup:
- Storage: 1.2TB (matching mainnet PebbleDB size)
- Hardware: i7ie.6xlarge (24 cores, 192GB RAM, 14TB NVMe)
- Dataset: 600M real-world KVs, 20,000 KV batches
- Read/Write ratio: 60% read / 40% write
- Background: PBSS flushing every 256 MB of accumulated trie data
Observations
- Trie Reads: Slightly slower in single-thread mode, but 12.4% faster under multi-threading.
- Write Batches: Major performance gains — 71–75% faster across both single and multi-threaded environments.
These results confirm Scalable DB’s readiness for mainnet-scale performance and its ability to sustain high throughput as the network grows.
Summary
Scalable DB is designed to support BSC’s next generation of performance, scalability, and reliability.
As state growth continues, this architecture ensures the network remains fast and efficient — even under massive data loads.
Key Benefits
- Stable performance at scale: Multi-DB design avoids hardware bottlenecks and maintains consistent throughput.
- Parallel performance: Up to 70% faster writes and 60% faster multi-threaded reads with sharding.
- Improved execution: Dedicated snapshot DB reduces read latency by ~5% when SnapDB size reaches ~1.5 TiB on NVMe disks.
- Better disk utilization: Operators can assign DBs to different storage types (e.g., SnapDB on NVMe, IndexDB on SSD).
- Custom configurations: Each DB can be optimized for its workload — block data, trie nodes, or snapshots.
Scalable DB marks a major leap in BNB Smart Chain’s evolution—built for growth, engineered for speed, and designed to last.
Follow us to stay updated on everything BNB Chain
Website | Twitter | Telegram | Facebook | dApp Store | YouTube | Discord | LinkedIn | Build N' Build Forum